บทความโดย ดร. วิรินทร์ เมฆประดิษฐสิน
” การทำความเข้าใจ Artificial Intelligence ในยุคปัจจุบันไม่อาจจำกัดอยู่เพียงระดับของโมเดลหรืออัลกอริทึมอีกต่อไป หากแต่ต้องมองเห็นภาพรวมของ “ระบบนิเวศ AI” ทั้งหมด ตั้งแต่รากฐานทางพลังงาน โครงสร้างพื้นฐานการประมวลผล ไปจนถึงการนำไปใช้ในโลกจริง บทความนี้มีเป้าหมายเพื่อเปิดเผยโครงสร้างความสัมพันธ์เชิงพึ่งพิงขององค์ประกอบเหล่านี้อย่างเป็นระบบ เพื่อให้ผู้อ่านสามารถมองเห็น “ภาพใหญ่” ของ AI ได้อย่างชัดเจน และใช้เป็นกรอบในการตัดสินใจ ไม่ว่าจะอยู่ในบทบาทของผู้ออกแบบโครงสร้างพื้นฐาน ผู้พัฒนาโมเดล หรือผู้เลือกนำ AI ไปประยุกต์ใช้งานในบริบทต่าง ๆ
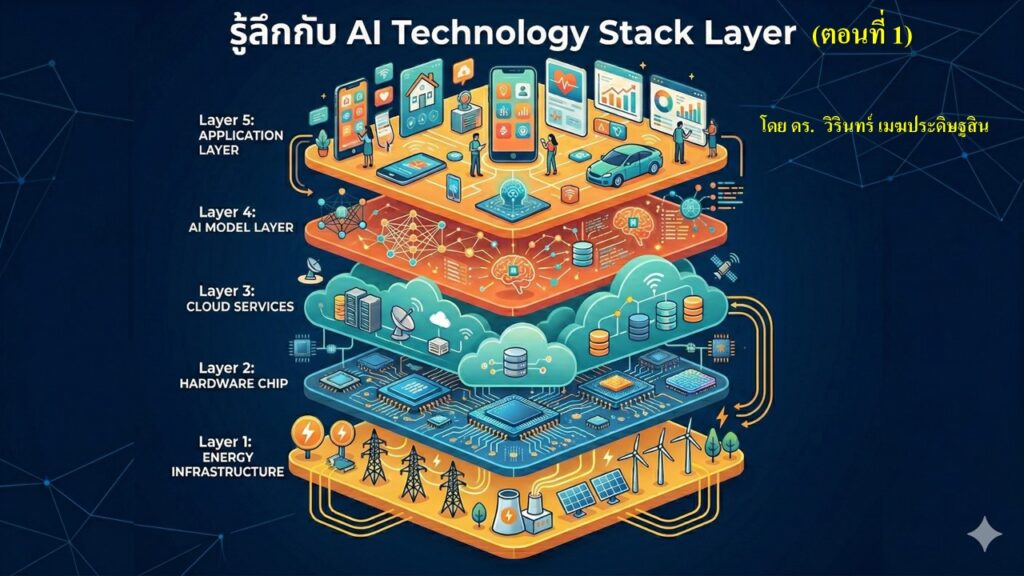
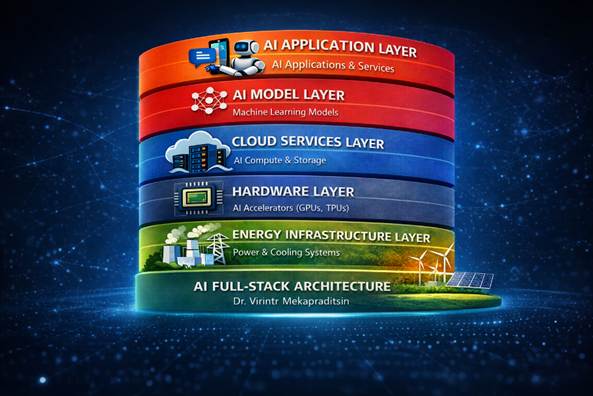
ในบทความนี้ ผมขอเสนอแนวคิด “AI Full-Stack Architecture” ซึ่งนิยามให้ AI เป็นสถาปัตยกรรมแบบหลายชั้น (multi-layered architecture) ที่มีความสัมพันธ์เชิงพึ่งพิงกันอย่างลึกซึ้ง โดยครอบคลุมตั้งแต่ Energy Infrastructure Layer, Chip/Compute Layer, Cloud & AI Infrastructure Layer, Data Layer, AI Model Layer ไปจนถึง Application Layer แนวคิดนี้มุ่งเน้นการทำความเข้าใจ AI ในฐานะระบบแบบองค์รวม (holistic system) ที่แต่ละชั้นทำหน้าที่ทั้งสนับสนุนและกำหนดขีดความสามารถของกันและกัน และทำหน้าที่เป็น “แผนที่นำทาง” สำหรับการออกแบบ พัฒนา และใช้ประโยชน์จาก AI อย่างมีประสิทธิภาพในยุคที่ AI กลายเป็นแกนหลักของการขับเคลื่อนองค์กรและสังคม”
AI Full-Stack Architecture Model
การเปลี่ยนผ่านของ AI จาก “เทคโนโลยีเฉพาะทาง” ไปสู่ “ระบบนิเวศแบบ Full-Stack”
ในอดีต Artificial Intelligence มักถูกทำความเข้าใจในฐานะศาสตร์หรือเทคโนโลยีเฉพาะด้านที่เกี่ยวข้องกับการพัฒนาอัลกอริทึม การสร้างโมเดล และการทำให้คอมพิวเตอร์สามารถเรียนรู้จากข้อมูลได้ดีขึ้น ไม่ว่าจะเป็น Machine learning, Deep learning หรือ Neural network ก็ตาม กรอบการมองเช่นนี้มีประโยชน์อย่างมากในยุคที่ AI ยังถูกจำกัดอยู่ในห้องทดลอง งานวิจัย หรือระบบเฉพาะกิจที่ยังไม่ต้องรองรับภาระงานในระดับขนาดใหญ่ แต่เมื่อ AI เริ่มแทรกซึมเข้าสู่ภาคธุรกิจ อุตสาหกรรม ภาครัฐ โครงสร้างพื้นฐานดิจิทัล และแม้แต่ชีวิตประจำวันของมนุษย์ การมอง AI ว่าเป็นเพียง “โมเดล” หรือ “ซอฟต์แวร์อัจฉริยะ” เริ่มไม่เพียงพออีกต่อไป เพราะในความเป็นจริง AI ที่ใช้งานได้ในโลกจริงต้องอาศัยองค์ประกอบมากมายตั้งแต่พลังงาน ชิปประมวลผล ระบบเครือข่าย Data Center แพลตฟอร์มคลาวด์ ข้อมูลจำนวนมหาศาล ตลอดจนระบบแอปพลิเคชันที่นำผลลัพธ์ของ AI ไปสร้างคุณค่าเชิงปฏิบัติ การเปลี่ยนผ่านนี้จึงทำให้ AI ต้องถูกอธิบายใหม่ในฐานะ “full-stack ecosystem” มากกว่าจะเป็นเทคโนโลยีชั้นเดียว
เหตุผลที่ต้องมีกรอบแนวคิดใหม่ในการอธิบาย AI
เมื่อ AI เติบโตขึ้นอย่างรวดเร็ว การวิเคราะห์ด้วยกรอบเดิมที่เน้นเฉพาะ model architecture เช่น จำนวนพารามิเตอร์ ประเภทของ transformer หรือวิธีการนำโมเดลที่ผ่านการฝึกฝนเบื้องต้นมาแล้ว (Pre-trained Model) ซึ่งมีความรู้กว้างๆ มหาศาล มาฝึกฝนเพิ่มเติมด้วยชุดข้อมูลเฉพาะทาง (Specific Dataset) ที่มีขนาดเล็กลง เพื่อให้โมเดลตอบสนองต่อโจทย์เฉพาะเรื่องได้อย่างแม่นยำ เริ่มสะท้อนภาพรวมของระบบได้ไม่ครบถ้วน เพราะแม้จะมีโมเดลที่ทรงพลังเพียงใด หากขาดพลังงานที่เพียงพอ ขาดชิปที่เหมาะสม ขาดโครงสร้างพื้นฐานสำหรับ training และ inference หรือขาดข้อมูลที่มีคุณภาพ โมเดลดังกล่าวก็ไม่อาจสร้างผลลัพธ์ในระดับที่ใช้งานได้จริงได้ ด้วยเหตุนี้ การสร้างกรอบแนวคิดใหม่จึงไม่ใช่เพียงการตั้งชื่อให้ดูทันสมัย แต่เป็นความจำเป็นทางวิชาการและวิศวกรรม เพื่อทำให้เราเข้าใจว่า AI เป็นระบบที่มีความพึ่งพิงเชิงลำดับชั้นอย่างชัดเจน แนวคิดของ AI Full Stack Architecture1 มาจากความพยายามในการยกระดับมุมมองจาก “AI as a model” ไปสู่ “AI as an interdependent architecture” ซึ่งช่วยให้การอธิบาย AI มีความสมบูรณ์ทั้งในมิติทางเทคนิค เศรษฐศาสตร์ โครงสร้างพื้นฐาน และการประยุกต์ใช้งาน


ภาพที่ 1 ภาพจาก helendarmi-hd.medium.com ภาพที่ 2 จาก TomsHardware.com
ที่มาของแนวคิดจากการสังเกตความสัมพันธ์เชิงพึ่งพิงของระบบ
หัวใจสำคัญของแนวคิดนี้เกิดจากการสังเกตว่า ความก้าวหน้าของ AI ในปัจจุบันไม่ได้ขับเคลื่อนไปแบบอิสระในแต่ละองค์ประกอบ แต่เป็นการพัฒนาแบบเชื่อมโยงและพึ่งพากันอย่างลึกซึ้ง ตัวอย่างเช่น การเติบโตของโมเดลขนาดใหญ่ไม่ได้เกิดขึ้นเพราะมีแนวคิดทางคณิตศาสตร์ที่ดีขึ้นเพียงอย่างเดียว แต่เกิดจากการที่โลกมีชิปประมวลผลประสิทธิภาพสูงขึ้น มี Data Center ขนาดใหญ่ขึ้น มีระบบ Cloud orchestration ที่มีประสิทธิภาพมากขึ้น และมีแหล่งข้อมูลในปริมาณที่เพียงพอสำหรับการฝึกสอนโมเดล เมื่อพิจารณาในภาพรวมจึงเห็นได้ว่า AI ไม่ใช่ระบบที่เติบโตจากบนลงล่างหรือจากล่างขึ้นบนเพียงทางเดียว แต่เป็นระบบที่ทุกชั้นมีผลต่อกันโดยตรง การสังเกตลักษณะ dependency เช่นนี้นำไปสู่ข้อสรุปว่า AI ควรถูกวิเคราะห์ในฐานะสถาปัตยกรรมหลายชั้นที่มีความสัมพันธ์กันอย่างเป็นระบบ ซึ่งกลายมาเป็นรากฐานของ AI Full-Stack Architecture Model
แนวคิดเรื่อง “Hierarchical Dependency” ใน AI Full-Stack Architecture
กรอบ AI Full-Stack Architectureตั้งอยู่บนสมมุติฐานสำคัญว่า AI เป็นสถาปัตยกรรมที่มีลักษณะเป็น hierarchical dependency กล่าวคือ แต่ละชั้นทำหน้าที่รองรับ ขยายขีดความสามารถ หรือในบางกรณีก็ทำหน้าที่จำกัดศักยภาพของชั้นถัดไปอย่างหลีกเลี่ยงไม่ได้ ชั้นล่างสุดอย่าง Energy Infrastructure Layer เป็นฐานของทุกสิ่ง เพราะหากไม่มีพลังงานที่มั่นคงเพียงพอ ก็ไม่สามารถรองรับ Data Center หรือระบบประมวลผลความหนาแน่นสูงได้ จากนั้น Chip/Compute Layer จะเป็นตัวแปรสำคัญในการแปลงพลังงานให้กลายเป็นศักยภาพการคำนวณ ขณะที่ Cloud & AI Infrastructure Layer ทำหน้าที่รวบรวมและจัดระเบียบทรัพยากรประมวลผลให้สามารถใช้งานในระดับขนาดใหญ่ได้ ส่วน Data Layer ทำหน้าที่เป็นเชื้อเพลิงเชิงความรู้ให้กับโมเดล เมื่อโมเดลถูกฝึกจนมีศักยภาพแล้ว ก็ยังต้องอาศัย Application Layer ในการเชื่อมต่อผลลัพธ์กับกระบวนการทำงานจริงของมนุษย์หรือองค์กร ดังนั้นคำว่า dependency ในที่นี้ไม่ได้หมายถึงเพียง “ต้องใช้ร่วมกัน” แต่หมายถึง “ความสามารถของชั้นหนึ่งถูกกำหนดโดยคุณสมบัติและข้อจำกัดของอีกชั้นหนึ่งอย่างมีโครงสร้าง”
เหตุใด AI จึงไม่ควรถูกมองแบบ Model-Centric เพียงอย่างเดียว
ในแวดวงวิชาการและอุตสาหกรรมเทคโนโลยี มีแนวโน้มที่ผู้คนจะให้ความสำคัญกับ AI Model Layer มากที่สุด เพราะเป็นชั้นที่มองเห็นผลลัพธ์ได้เด่นชัดที่สุด เช่น ความสามารถในการตอบคำถาม สร้างภาพ วิเคราะห์ข้อมูล หรือทำ reasoning อย่างไรก็ตาม การมองเพียงชั้นของโมเดลอาจทำให้เกิดความเข้าใจที่คลาดเคลื่อนว่า หากมีโมเดลที่ฉลาดขึ้น ทุกสิ่งจะดีขึ้นตามไปด้วย ทั้งที่ในความเป็นจริง โมเดลเป็นเพียงส่วนหนึ่งของห่วงโซ่ทั้งหมดเท่านั้น โมเดลที่ยอดเยี่ยมแต่รันบนโครงสร้างพื้นฐานที่ไม่เสถียร ใช้ข้อมูลคุณภาพต่ำ หรือถูกนำไปฝังใน workflow ที่ไม่เหมาะสม ย่อมไม่สามารถสร้างคุณค่าที่แท้จริงได้ มุมมองแบบ model-centric จึงมีข้อจำกัดในเชิงวิเคราะห์ เพราะไม่สามารถอธิบายได้ว่าทำไมบางองค์กรมีโมเดลคล้ายกัน แต่กลับสร้างคุณค่าทางธุรกิจได้ต่างกันอย่างมาก AI Full-Stack Architectureจึงช่วยขยายมุมมองไปสู่ระบบเต็ม Stack เพื่อทำให้เข้าใจว่า “ความฉลาดของ AI” ไม่ได้อยู่ในโมเดลล้วน ๆ แต่อยู่ในความสอดประสานการทำงานของทุกชั้นร่วมกัน
การแยก AI ออกเป็น 5 Layer มีความหมายเชิงวิชาการอย่างไร
การจำแนก AI ออกเป็น 5 Layer ใน สถาปัตยกรรมแบบ AI Full Stack ไม่ใช่เพียงการจัดหมวดหมู่เพื่อความสะดวกในการอธิบายเท่านั้น แต่มีความหมายเชิงวิชาการอย่างยิ่ง เพราะช่วยให้สามารถศึกษาปรากฏการณ์ของ AI ได้อย่างมีโครงสร้างและวิเคราะห์ได้ทั้งในแนวดิ่งและแนวนอน ในแนวดิ่ง เราสามารถมองเห็นความต่อเนื่องตั้งแต่พลังงานไปจนถึงการประยุกต์ใช้งาน และเข้าใจได้ว่าเหตุใดปัญหาในชั้นล่างจึงส่งผลกระทบต่อชั้นบน ในแนวนอน เราสามารถเจาะวิเคราะห์ภายในแต่ละชั้นได้ลึกขึ้น เช่น ปัญหาด้านพลังงาน ปัญหาด้าน chip supply chain ปัญหาด้าน cloud scalability ปัญหาด้าน data governance ปัญหาด้าน model alignment หรือปัญหาด้าน application integration การแบ่ง 5 Layer จึงช่วยให้ AI กลายเป็นระบบที่สามารถศึกษา ออกแบบ ประเมิน และวิพากษ์ได้อย่างเป็นระบบ แทนที่จะมองเป็นเทคโนโลยีที่กระจัดกระจายหรือถูกอธิบายแบบแยกส่วน
ภาพที่ 3 Layer 1 : Energy Infrastructure Layer
ความหมายและบทบาทเชิงโครงสร้างของ Energy Infrastructure Layer
Energy Infrastructure Layer เป็นชั้นพื้นฐานที่สุดของสถาปัตยกรรม AI Full-Stack Architecture และทำหน้าที่เป็น “physical substrate” ที่รองรับการทำงานของระบบ AI ทั้งหมด กล่าวอีกนัยหนึ่ง AI ไม่ได้เริ่มต้นจากข้อมูลหรือโมเดล แต่เริ่มต้นจาก “พลังงาน” ที่ทำให้ระบบคอมพิวเตอร์สามารถทำงานได้จริงในโลกกายภาพ การมีอยู่ของ Cloud Data center, GPU cluster หรือ Cloud platform ล้วนตั้งอยู่บนเงื่อนไขสำคัญคือการมีพลังงานไฟฟ้าที่เพียงพอ เสถียร และต่อเนื่อง ดังนั้น Energy Layer จึงไม่ใช่เพียงองค์ประกอบสนับสนุน แต่เป็น “constraint layer” ที่กำหนดเพดานของขีดความสามารถของ AI ในทุกระดับ (IEA, 2023)
พลังงานในฐานะข้อจำกัดหลักของการเติบโตของ AI
ในยุคของ large-scale AI โดยเฉพาะ foundation models และ generative AI ความต้องการพลังงานเพิ่มขึ้นอย่างก้าวกระโดด ตัวอย่างเช่น การฝึก GPT-3 มีการใช้พลังงานประมาณ 1,287 MWh ภายใต้โครงสร้างพื้นฐานที่มี PUE ประมาณ 1.10 และใช้ GPU จำนวนมากในระดับหลายพันถึงหมื่นตัว (Patterson et al., 2021) การฝึกโมเดลในระดับนี้จึงเทียบเท่ากับ workload ของ Data center ขนาดใหญ่ และต้องใช้กำลังไฟฟ้าเฉลี่ยระดับหลายเมกะวัตต์อย่างต่อเนื่อง การวิเคราะห์เชิงระบบจึงแสดงให้เห็นว่า AI ไม่ได้ถูกจำกัดด้วย algorithm เพียงอย่างเดียว แต่ถูกจำกัดด้วยความสามารถในการจัดหาและบริหารพลังงาน ซึ่งทำให้ energy กลายเป็น “hidden bottleneck” ของการพัฒนา AI
องค์ประกอบของโครงสร้างพื้นฐานด้านพลังงานสำหรับ AI
Energy Infrastructure Layer ประกอบด้วยหลายองค์ประกอบที่ทำงานร่วมกันเป็นระบบ ตั้งแต่ต้นน้ำถึงปลายน้ำ โดยเริ่มจาก Power Generation เช่น โรงไฟฟ้าที่ใช้พลังงานฟอสซิล พลังงานนิวเคลียร์ พลังงานหมุนเวียน ต่อด้วย Power Transmission และ Distribution ผ่าน grid และ สถานีย่อย ไปยัง Data Centerและภายใน Data Center เองยังมีระบบย่อยที่สำคัญ ได้แก่ Uninterruptible Power Supply (UPS), Power Distribution Unit (PDU), redundant power path และ backup generator ซึ่งทั้งหมดนี้ถูกออกแบบเพื่อให้ระบบสามารถทำงานได้อย่างต่อเนื่องแม้เกิดความผิดปกติ นอกจากนี้ยังต้องมีระบบจัดการพลังงานแบบ real-time เพื่อควบคุม load balancing และป้องกัน overload ในระดับ rack และ server อีกด้วย (Shehabi et al., 2016)

ภาพที่ 4 Liquid Cooling สำหรับ Data Center สมัยใหม่ (ภาพจาก Tomshardware.com)
ความสัมพันธ์ระหว่างพลังงานกับระบบระบายความร้อน
พลังงานที่ถูกใช้ในการประมวลผลของ AI จะถูกแปลงเป็นความร้อนในสัดส่วนที่สูงมาก ดังนั้นปัญหาพลังงานจึงไม่สามารถแยกออกจากปัญหาความร้อนได้ ระบบประมวลผล AI ที่ใช้ GPU ความหนาแน่นสูง จำเป็นต้องมีระบบ cooling ที่มีประสิทธิภาพ เช่น air cooling, liquid cooling หรือแม้แต่ immersion cooling ในระดับ hyperscale ความสามารถในการระบายความร้อน กลายเป็นตัวกำหนดว่าระบบสามารถเพิ่มจำนวน GPU ต่อ rack ได้มากเพียงใด หาก cooling ไม่เพียงพอ ต่อให้มีพลังงานไฟฟ้าเหลือ ระบบก็ไม่สามารถใช้งานคำนวณ ประมวลผลได้เต็มที่ ดังนั้นในมุมมองของ AI Full-Stack Architectureพลังงานและความร้อนต้องถูกพิจารณาเป็นระบบควบคู่กัน ที่แยกออกจากกันไม่ได้
Power Density และข้อจำกัดของ Data Centerยุค AI
การเพิ่มขึ้นของ AI workload ทำให้ power density ของ data center เพิ่มขึ้นอย่างมีนัยสำคัญ จากเดิมที่ rack ใช้ไฟเพียง 5–10 kW ในยุค enterprise IT ปัจจุบัน rack สำหรับ AI อาจใช้มากกว่า 30–80 kW หรือสูงกว่านั้น โดยเฉพาะในระบบที่ใช้ GPU cluster เช่น DGX systems ของ NVIDIA ซึ่งมีการใช้พลังงานต่อเครื่องในระดับ 10–14 kW (NVIDIA, 2024; NVIDIA, 2025) การเพิ่มขึ้นของ power density นี้ทำให้เกิดข้อจำกัดด้านพื้นที่ การระบายความร้อน และการออกแบบโครงสร้างพื้นฐานไฟฟ้า ซึ่งส่งผลโดยตรงต่อ scalability ของ AI system
Renewable Energy และความยั่งยืนของ AI
เมื่อ AI ใช้พลังงานมากขึ้นอย่างต่อเนื่อง ประเด็นด้านความยั่งยืน จึงกลายเป็นปัจจัยสำคัญ Energy Infrastructure Layer ในยุคใหม่ไม่ได้พิจารณาเพียงความเพียงพอของพลังงาน แต่รวมถึงแหล่งที่มาของพลังงานด้วย การใช้ renewable energy เช่น solar, wind หรือ hydro power เริ่มมีบทบาทมากขึ้นใน Hyperscale Data Center อย่างไรก็ตาม renewable energy มีข้อจำกัดด้านความสม่ำเสมอ ซึ่งทำให้ต้องมีระบบ energy storage เช่น battery หรือ hybrid grid เข้ามาช่วยจัดการ การออกแบบ AI infrastructure ในอนาคตจึงต้องคำนึงถึงทั้ง “ประสิทธิภาพต่อวัตต์” และ “ปริมาณ carbon ที่ถูกปลดปล่อยต่อหนึ่งการประมวลผล” พร้อมกัน
ความสัมพันธ์ระหว่าง Energy Layer กับ Chip/Compute Layer
Energy Infrastructure Layer มีความสัมพันธ์โดยตรงกับ Hardware Chip Layer (Layer ที่ 2) ผ่านแนวคิด “ประสิทธิภาพต่อวัตต์” ซึ่งเป็นตัวชี้วัดสำคัญในระบบ AI ยิ่งชิปสามารถประมวลผลได้มากขึ้นต่อหน่วยพลังงาน ก็ยิ่งทำให้ระบบโดยรวมมีประสิทธิภาพสูงขึ้น ในทางกลับกัน หากชิปมีประสิทธิภาพต่ำหรือใช้พลังงานมากเกินไป จะทำให้ต้นทุนพลังงานสูงขึ้นอย่างรวดเร็วในระดับ Data Centerดังนั้นการพัฒนา AI hardware ในปัจจุบันจึงมุ่งเน้นที่การลดการใช้พลังงานต่อหนึ่งการปฏิบัติงานมากขึ้น ไม่ใช่เพียงเพิ่ม FLOPS อย่างเดียว ตัวอย่างเช่น DGX systems ของ NVIDIA ถูกออกแบบเพื่อให้มี throughput สูงต่อหน่วยพลังงาน ซึ่งสะท้อนถึงการออกแบบให้ทำงานร่มกันระหว่าง energy และ compute layer (NVIDIA, 2024) ความสัมพันธ์นี้สะท้อนให้เห็นว่า Energy Layer ไม่ได้เป็นเพียงฐานล่าง แต่มีอิทธิพลต่อทิศทางการออกแบบ chip architecture โดยตรง
Energy-Aware AI และแนวโน้มในอนาคต
แนวโน้มสำคัญที่เริ่มปรากฏชัดคือการพัฒนา “energy-aware AI systems” ซึ่งหมายถึงการออกแบบทั้งโมเดล อัลกอริทึม และ infrastructure โดยคำนึงถึงการใช้พลังงานเป็นปัจจัยหลัก เช่น การใช้วิธีการบีบอัด model การลดความละเอียดของตัวเลข การตัดการเชื่อมต่อที่ไม่สำคัญกับ Model ออกไป หรือ การประมวลผลแบบปรับตัวตามความยาก เพื่อลดการใช้พลังงานต่อการประมวลผล นอกจากนี้ยังมีแนวคิดในการย้าย workload ไปยัง edge หรือ region ที่มีพลังงานเหลือใช้ หรือมีต้นทุนพลังงานต่ำกว่า ซึ่งสะท้อนว่าในอนาคต การจัดการพลังงานจะกลายเป็นส่วนหนึ่งของการออกแบบ AI system ไม่ใช่เพียงปัจจัยภายนอก
มุมมองเชิงยุทธศาสตร์: พลังงานในฐานะอำนาจของ AI ระดับประเทศ
ในระดับมหภาค Energy Infrastructure Layer มีนัยสำคัญเชิงยุทธศาสตร์อย่างยิ่ง ประเทศหรือองค์กรที่สามารถควบคุมแหล่งพลังงานและโครงสร้างพื้นฐานด้านพลังงานได้ จะมีข้อได้เปรียบในการพัฒนา AI อย่างมหาศาล เพราะสามารถสร้างและขยาย Data Centerได้โดยไม่ติดข้อจำกัดด้านพลังงาน การแข่งขันด้าน AI ในอนาคตจึงไม่ใช่เพียงการแข่งขันด้านทักาะความสามารถ หรือ algorithm แต่เป็นการแข่งขันด้าน “ขีดความสามารถด้านพลังงาน” และ “อธิปไตยทางโครงสร้างพื้นฐาน หรืออำนาจเบ็ดเสร็จในการควบคุมและจัดการโครงสร้างพื้นฐานด้วยตนเอง” ซึ่งทำให้ Energy Layer กลายเป็นหนึ่งในปัจจัยกำหนดอำนาจทางเทคโนโลยีในระดับโลก (IEA, 2023)
บทสรุปเชิงแนวคิดของ Energy Infrastructure Layer
Energy Infrastructure Layer ในกรอบของ AI Full-Stack Architecture ทำหน้าที่เป็นทั้ง “foundation” และ “constraint” ของระบบ AI ทั้งหมด โดยกำหนดว่าระบบสามารถขยายตัวได้มากเพียงใด มีความเสถียรเพียงใด และมีต้นทุนเท่าใด การมอง AI โดยไม่พิจารณาพลังงานจึงเป็นการมองที่ไม่สมบูรณ์ เพราะความสามารถของ AI ในโลกจริงถูกกำหนดโดยความสามารถในการจัดหา แปลง และบริหารพลังงานอย่างมีประสิทธิภาพ ดังนั้น Energy Layer จึงไม่ใช่เพียงจุดเริ่มต้นของสถาปัตยกรรม แต่เป็นแกนที่เชื่อมโยงโลกกายภาพเข้ากับโลกดิจิทัล และเป็นรากฐานที่ทำให้ AI สามารถดำรงอยู่และเติบโตได้อย่างแท้จริง
กรณีศึกษา : Energy Infrastructure Layer ในโลกความเป็นจริงของระบบ AI
1. กรณีศึกษา : OpenAI — การขยายขนาดพลังงานใน Large Language Model Training

ภาพที่ 5 จาก Business Analytics Review – substack
การพัฒนาโมเดลขนาดใหญ่ของ OpenAI เช่น GPT-series เป็นตัวอย่างที่ชัดเจนของการที่ Energy Infrastructure Layer กลายเป็นข้อจำกัดเชิงระบบ อย่างแท้จริง ในการฝึกโมเดลระดับหลายแสนล้านพารามิเตอร์ การประมวลผลไม่ได้เกิดขึ้นเพียงในระดับเครื่องเดียว แต่เกิดขึ้นใน Cluster ของ GPU จำนวนหลายพันถึงหลายหมื่นตัวที่ทำงานแบบขนาน (massively parallel computation) ซึ่งนำไปสู่การใช้พลังงานในระดับ megawatt อย่างต่อเนื่องเป็นระยะเวลาหลายสัปดาห์หรือหลายเดือน สิ่งที่สำคัญคือ การออกแบบ training pipeline ของโมเดลจึงไม่ใช่เพียงปัญหาทาง algorithm หรือการประมวลผลเชิงกระจายเท่านั้น แต่ยังเป็นปัญหาทาง “energy scheduling” และ “thermal management” อีกด้วย กล่าวคือ ต้องมีการวางแผนการใช้พลังงานอย่างมีประสิทธิภาพ เพื่อหลีกเลี่ยง peak load ที่อาจทำให้ระบบไม่เสถียร หรือทำให้ต้นทุนพลังงานเพิ่มขึ้นอย่างมหาศาล
ในเชิงวิเคราะห์กรณีของ OpenAI แสดงให้เห็นว่า “ความสามารถในการ train model ขนาดใหญ่” ไม่ได้ขึ้นอยู่กับความรู้ด้าน AI เพียงอย่างเดียว แต่ขึ้นอยู่กับการเข้าถึง infrastructure ที่มีพลังงานเพียงพอและมีระบบระบายความร้อนที่มีประสิทธิภาพสูง ความได้เปรียบขององค์กรจึงไม่ได้อยู่ที่ algorithm เพียงอย่างเดียว แต่รวมถึงความสามารถในการใช้ทรัพยากรพลังงานอย่างมีประสิทธิภาพด้วย ในบริบทของ AI Full-Stack Architectureกรณีนี้สะท้อนว่า ระดับชั้นพลังงาน (Energy Layer) คือผู้กำหนด ‘เพดานสูงสุด’ ให้กับ AI อย่างแท้จริง เพราะท้ายที่สุดแล้ว ขนาดและความฉลาดล้ำลึกของโมเดล ย่อมไม่อาจก้าวข้ามขีดจำกัดของทรัพยากรพลังงานที่ระบบจะจัดหาและบริหารจัดการได้
2. กรณีตัวอย่าง : Google — Hyperscale Data Centerand การใช้พลังงานอย่างมีประสิทธิภาพ

ภาพที่ 6 จาก Linkedin
Google เป็นหนึ่งในองค์กรที่แสดงให้เห็นถึงการจัดการ Energy Infrastructure Layer อย่างมีประสิทธิภาพในระดับ hyperscale โดยเฉพาะการใช้ AI มาช่วย เพิ่มประสิทธิภาพ การใช้พลังงานใน Data Centerของตนเอง ระบบของ Google ใช้ Machine learning ในการควบคุมระบบ cooling เพื่อลดการใช้พลังงานลงอย่างมีนัยสำคัญ (เช่น ลดการบริโภคพลังงานของระบบทำความเย็นได้หลายสิบเปอร์เซ็นต์ในบางกรณี) สะท้อนให้เห็นว่า Energy Layer ไม่ได้ทำหน้าที่เป็นเพียงข้อจำกัดทางกายภาพเท่านั้น แต่กำลังวิวัฒนาการไปสู่ ‘Optimization Domain’ หรือพื้นที่ยุทธศาสตร์ใหม่ที่ AI สามารถย้อนกลับลงไปช่วยบริหารจัดการและเพิ่มประสิทธิภาพการใช้พลังงานด้วยตัวมันเอง เกิดเป็นวงจรแห่งการพัฒนาที่ชาญฉลาดและยั่งยืน
ในเชิงสถาปัตยกรรม Data Centerของ Google ถูกออกแบบให้มีค่า Power Usage Effectiveness (PUE) ต่ำมาก ซึ่งหมายถึงสัดส่วนพลังงานที่ใช้ไปกับการประมวลผลจริงมีประสิทธิภาพสูงเมื่อเทียบกับพลังงานทั้งหมดที่ใช้ในระบบ (รวมระบบ cooling และ overhead อื่น ๆ) แนวคิดนี้ถือเป็นหัวใจสำคัญของ AI Full-Stack Architectureเพราะประสิทธิผลในชั้น Energy Layer คือตัวแปรต้นที่ส่งผลโดยตรงต่อต้นทุน และการขยายตัว ของระบบ AI ทั้งระบบ การลดภาระส่วนเกิน (Overhead) ของพลังงานลงได้ จึงเท่ากับการปลดล็อกขีดความสามารถในการประมวลผล ให้ทะยานไปได้ไกลขึ้น โดยไม่สร้างภาระด้านพลังงานเพิ่มตามอย่างมีนัยสำคัญ
3. กรณีศึกษา : NVIDIA DGX Cluster — High-Density AI Compute and Power Design

ภาพที่ 7 NVIDIA DGX B200 (จาก NVIDIA)

ภาพที่ 8 NVIDIA DGX Spark (ภาพจาก NVIDIA)
ระบบ DGX ของ NVIDIA เป็นตัวอย่างของการออกแบบ Chip/Compute Layer ที่ต้องทำงานสอดประสานกับ Energy Infrastructure Layer อย่างใกล้ชิด โดย DGX system หนึ่งเครื่องสามารถใช้พลังงานในระดับหลายกิโลวัตต์ (kW) และเมื่อรวมกันเป็น cluster ใน Data Centerจะทำให้เกิด power density สูงมากในระดับ rack ซึ่งอาจเกิน 30–80 kW ต่อ rack หรือมากกว่านั้นในบาง configuration ความท้าทายจึงไม่ได้อยู่ที่การเพิ่มจำนวน GPU เพียงอย่างเดียว แต่คือการออกแบบระบบจ่ายไฟ (power delivery) และระบบระบายความร้อนที่สามารถรองรับความหนาแน่นของพลังงานในระดับนี้ได้
ในเชิงวิศวกรรม DGX cluster ยังสะท้อนให้เห็นถึงความสำคัญของ “ประสิทธิภาพต่อวัตต์” อย่างชัดเจน เพราะแม้จะเพิ่มขีดความสามารถด้านประมวลผลได้ แต่หากใช้พลังงานมากเกินไป จะทำให้ต้นทุนรวมของระบบเพิ่มขึ้นอย่างไม่ยั่งยืน NVIDIA จึงมุ่งเน้นการออกแบบ architecture ที่สามารถให้ throughput สูงสุดต่อหน่วยพลังงาน พร้อมทั้งพัฒนา interconnect เช่น NVLink เพื่อลด latency และเพิ่ม efficiency ของการสื่อสารระหว่าง GPU สิ่งนี้แสดงให้เห็นว่า Energy Layer และ Chip Layer ไม่ได้แยกจากกัน แต่เป็นระบบที่ถูกออกแบบมาให้ทำงานร่วมกันอย่างใกล้ชิด
Comparative Analysis: บทเรียนจากทั้ง 3 กรณีศึกษา
เมื่อพิจารณาทั้งสามกรณีร่วมกัน จะเห็นรูปแบบร่วมที่สำคัญสามประการ ประการแรกคือ “Energy as a Scaling Constraint” ทั้ง OpenAI และ NVIDIA แสดงให้เห็นว่าการขยายขนาดของ AI ถูกจำกัดโดยความสามารถในการจัดหาและจัดการพลังงาน ประการที่สองคือ “Energy as an Optimization Domain” ซึ่ง Google แสดงให้เห็นว่า energy efficiency สามารถถูกปรับปรุงได้ด้วย AI เอง ประการที่สามคือ “การอกแบบให้มีการทำงานร่วมกันระหว่าง Layers” กล่าวคือ การออกแบบ chip, infrastructure และ energy system ต้องทำร่วมกัน ไม่สามารถแยกพิจารณาได้อย่างอิสระ
บทสรุปเชิงวิชาการของ Case Study
Case Study ทั้งสามนี้จะเห็นอย่างชัดเจนว่า Energy Infrastructure Layer ไม่ได้เป็นเพียงพื้นฐานทางกายภาพ แต่เป็นตัวแปรเชิงกลยุทธ์ที่กำหนดขีดความสามารถของระบบ AI ทั้งหมด ตั้งแต่การฝึกโมเดล การให้บริการ ไปจนถึงต้นทุนและความยั่งยืนของระบบ ในโลกของ AI ยุคใหม่ ผู้ที่สามารถควบคุมและบริหารพลังงานได้อย่างมีประสิทธิภาพ จะเป็นผู้ที่สามารถสร้างและขยาย AI ได้ในระดับที่เหนือกว่าผู้อื่น ดังนั้น Energy Layer จึงควรถูกยกระดับจาก “supporting infrastructure” ไปสู่ “core architectural component” ในการวิเคราะห์และออกแบบระบบ AI อย่างแท้จริง
Case Study เชิงตัวเลขของ Energy Infrastructure Layer
1) OpenAI / GPT-3: ตัวเลขพลังงานและต้นทุนการฝึกโมเดล
สำหรับฝั่ง OpenAI นั้น ตัวเลขต้นทุนจริงของการฝึก GPT-3 ไม่ได้ถูกเปิดเผยอย่างเป็นทางการแบบละเอียดในลักษณะใบแจ้งค่าใช้จ่ายจริงต่อรอบการ Train แต่มีตัวเลขสาธารณะที่ใช้อ้างอิงกันมากจากทั้งงานวิจัยและงานวิเคราะห์ภายนอก โดยจุดที่มีน้ำหนักมากที่สุดคือ งานของ Patterson และคณะ ซึ่งระบุว่า GPT-3 มีการใช้พลังงานในการฝึกประมาณ 1,287 MWh และปล่อยคาร์บอนประมาณ 552 tCO2e. งานเดียวกันยังระบุด้วยว่า OpenAI ให้ข้อมูลว่าศูนย์ข้อมูลที่ใช้มี PUE = 1.10, ใช้ V100 จำนวนประมาณ 10,000 ตัว, GPU แต่ละตัวมีการใช้ไฟเฉลี่ยระหว่างรันงานราว 330 W, และการฝึกในสมมติฐานดังกล่าวจะใช้เวลาประมาณ 14.8 วัน สำหรับปริมาณคอมพิวต์รวม 3.14×10^23 FLOPs. เมื่อนำตัวเลขนี้มาวิเคราะห์ในเชิงโครงสร้างพื้นฐาน จะได้ว่า GPT-3 ไม่ได้เป็นเพียง “โมเดลขนาดใหญ่” แต่เป็น workload ระดับ Data Centerอย่างแท้จริง โดยกำลังไฟเฉลี่ยระดับ facility อยู่ราว 3.62 MW ตลอดช่วงการฝึกตามประมาณการนี้
ในมุมของต้นทุนการฝึก ควรแยกให้ชัดระหว่างต้นทุนอย่างเป็นทางการกับ การประมาณการณ์เชิงสาธารณะ ตัวเลขที่ถูกอ้างถึงมากคือการประเมินของ Lambda ว่า GPT-3 หากคิดแบบ cloud cost บน Tesla V100 จะมีค่าใช้จ่าย “มากกว่า 4.6 ล้านดอลลาร์สหรัฐ” ต่อการ train หนึ่งครั้ง. ขณะที่งานวิจัยปี 2024 เรื่อง The rising costs of training frontier AI models ให้ภาพที่เป็นระบบมากขึ้น โดยประเมินว่า amortized hardware cost ตลอดกระบวนการพัฒนาโมเดลของ GPT-3 อยู่ราว 4 ล้านดอลลาร์ ไม่ใช่เฉพาะค่าไฟ แต่รวมต้นทุนฮาร์ดแวร์ในเชิงคิดค่าเสื่อมและการใช้ทรัพยากรวิจัยด้วย ทั้งงานชิ้นเดียวกันยังชี้ว่าใน frontier models โดยเฉลี่ย “ค่าไฟ” มักเป็นเพียง 2–6% ของต้นทุนการพัฒนาโมเดลทั้งหมด แม้พลังงานจะเป็น bottleneck สำคัญก็ตาม.
2) Google Data Center: PUE และการลดพลังงานด้วย AI
ในกรณีของ Google จุดแข็งคือมีตัวเลขที่เป็นทางการจากผู้ให้บริการเองค่อนข้างชัดเจน ปัจจุบัน Google ระบุว่าในปี 2024 ค่าเฉลี่ย PUE ต่อปี ของ Data Center ทั้งหมดอยู่ที่ 1.09. ความหมายของตัวเลขนี้คือ ทุก ๆ 1 หน่วยพลังงานที่ใช้กับ IT equipment จะมี overhead ของ Data Centerเพิ่มอีกเพียง 0.09 หน่วยเท่านั้น ซึ่งถือว่ามีประสิทธิภาพสูงมากเมื่อเทียบกับค่าเฉลี่ยอุตสาหกรรมที่ Google อ้างว่าอยู่ที่ 1.56. Google ยังระบุด้วยว่าเมื่อเทียบกับค่าเฉลี่ยเชิงอุตสาหกรรมแล้ว Data Center ของตนใช้ overhead energy น้อยกว่าประมาณ 84% ต่อหน่วย IT energy. ตัวเลขนี้มีความสำคัญเชิงสถาปัตยกรรมอย่างมาก เพราะมันแสดงให้เห็นว่าการปรับปรุง Energy Infrastructure Layer ไม่ได้มีผลเพียงเรื่องสิ่งแวดล้อม แต่มีผลโดยตรงต่อ ขีดความสามารถในการประมวลผลที่ใช้จริง ของทั้งระบบด้วย
นอกจากนี้ Google และ DeepMind เคยเผยแพร่ผลการนำ Machine learning ไปปรับแต่งประสิทธิภาพ ระบบระบายความร้อนของ Data Centerโดยลดพลังงานที่ใช้เพื่อการ cooling ได้สูงสุดถึง 40% และลด overall PUE overhead ได้ 15% ในไซต์ที่ทดสอบจริง. กรณีนี้น่าสนใจมากในเชิง V-AFSAM เพราะมันแสดงให้เห็นว่า Energy Infrastructure Layer ไม่ใช่เพียงชั้นล่างสุดที่ถูก “ใช้” โดย AI เท่านั้น แต่ยังสามารถถูก “ปรับปรุง” ด้วย AI ได้ด้วย กล่าวคือ AI กลายเป็นทั้งผู้บริโภคพลังงานและผู้ช่วยเพิ่มประสิทธิภาพพลังงานในเวลาเดียวกัน นี่คือภาพของ วงจรป้อนกลับหรือ feedback loop ระหว่างชั้น Application/Model กับชั้น Energy ที่มีนัยสำคัญมากต่อสถาปัตยกรรม AI ยุคถัดไป (ข้อมูลจาก Blog.google)
3) NVIDIA DGX H100: ตัวเลขการใช้ไฟของระบบ AI ระดับองค์กร
สำหรับฝั่ง NVIDIA มีข้อมูลทางเทคนิคที่เป็นทางการชัดเจนมากกว่าในระดับเครื่องและคลัสเตอร์ โดยคู่มือ DGX H100/H200 ระบุว่า DGX H100/H200 หนึ่งระบบมี power supplies 6 ตัว และมี system power สูงสุด 10.2 kW. ถ้านำตัวเลขนี้มาแปลงเป็นการใช้พลังงานแบบต่อเนื่อง จะได้ประมาณ 244.8 kWh ต่อวัน และประมาณ 7,344 kWh ต่อ 30 วัน หากรันใกล้โหลดสูงสุดตลอดเวลา. ตัวเลขนี้ยังไม่รวม overhead ของ Data Centerเช่น cooling และ power distribution; ถ้าคิดที่ PUE 1.10 แบบ hyperscaler ซึ่งเป็นระดับดีมาก พลังงานรวมระดับ facility จะขึ้นเป็นราว 269.3 kWh/วัน และที่ PUE 1.25 จะขึ้นเป็นราว 306.0 kWh/วัน. ดังนั้นแม้จะเป็นเพียง “หนึ่งเครื่อง” แต่ในทางปฏิบัติมันคือโหลดระดับอุตสาหกรรมขนาดย่อมแล้ว
เมื่อขยายจากระดับเครื่องสู่ระดับ rack หรือ cluster ความหมายของตัวเลขนี้จะยิ่งชัดขึ้น เช่น หากมี DGX H100 จำนวน 32 ระบบที่แต่ละระบบใช้ไฟเต็มใกล้เคียง 10.2 kW จะได้โหลด IT ประมาณ 326.4 kW; หากคิด PUE 1.10 ก็จะเป็นโหลดระดับ facility ราว 359 kW และถ้ารันต่อเนื่อง 30 วันจะใช้พลังงานรวมประมาณ 258 MWh. นี่แสดงให้เห็นชัดว่าทันทีที่องค์กรเริ่มขยับจาก “มี AI server” ไปสู่ “มี AI cluster” โจทย์จะเปลี่ยนจากการจัดหาของเซิร์ฟเวอร์ไปเป็นโจทย์ด้านไฟฟ้า หม้อแปลง UPS ระบบระบายความร้อน และความสามารถของห้อง Data Centerอย่างหลีกเลี่ยงไม่ได้ ซึ่งตรงกับแกนความคิดของ Energy Infrastructure Layer ใน V-AFSAM โดยสมบูรณ์ (จาก NVIDIA Docs)
4) NVIDIA DGX B200: การขยับสู่ power density ที่สูงขึ้น
NVIDIA ระบุบนหน้าผลิตภัณฑ์ว่า DGX B200 มี system power usage ~14.3 kW max ต่อระบบ ซึ่งสูงกว่า DGX H100 อย่างมีนัยสำคัญ. ถ้าคำนวณแบบเดียวกัน จะได้ประมาณ 343.2 kWh ต่อวัน หรือราว 10,296 kWh ต่อ 30 วัน ต่อเครื่องที่โหลดสูงสุดอย่างต่อเนื่อง. หากองค์กรติดตั้งเพียง 10 ระบบ ก็จะได้โหลด IT สูงสุดประมาณ 143 kW; ถ้า 100 ระบบ จะกลายเป็น 1.43 MW เฉพาะด้าน IT load เท่านั้น และเมื่อรวม PUE แล้วโหลด facility จะสูงกว่านี้อีก. ตัวเลขนี้มีความหมายเชิงยุทธศาสตร์มาก เพราะสะท้อนว่าความก้าวหน้าของ Compute Layer กำลังผลักให้ Energy Layer ต้องวิวัฒน์ตาม ทั้งในด้าน rack density, liquid cooling, power delivery และการจัดสรรโหลดใน Data Centerรุ่นใหม่
หากพิจารณาตัวเลขของ DGX B200 จะพบแนวโน้มสำคัญของระบบ AI สมัยใหม่ว่า Compute Growth ไม่ได้ขยับตัวตาม Cost Growth เป็นเส้นตรงเสมอไป แต่สิ่งที่น่ากังวลกว่าคือ Power Density Growth ที่พุ่งสูงขึ้นอย่างก้าวกระโดด กล่าวคือ แม้องค์กรอาจใช้จำนวนเครื่องน้อยลงเพื่อให้ได้ Throughput ที่มหาศาลขึ้น แต่ผลที่ตามมาคือความหนาแน่นของกำลังไฟฟ้าและการแผ่รังสีความร้อนต่อ Rack จะทวีความรุนแรงขึ้นจนกลายเป็นโจทย์ใหม่ด้านวิศวกรรม ดังนั้นในบริบทของ AI Full-Stack Architecture สามารถอธิบายได้ว่า การเปลี่ยนผ่านจาก DGX H100 ไปสู่ DGX B200 ไม่ได้เป็นเพียงการเปลี่ยน generation ของ accelerator แต่เป็นการเปลี่ยน “energy regime” ของ AI infrastructure ด้วย (ข้อมูลจาก NVIDIA)