
แนวทางการวางแผนกู้คืนระบบ (Disaster Recovery Planning)
ความเสี่ยงจากภัยพิบัติที่เกิดจากธรรมชาติ และน้ำมือมนุษย์เป็นสิ่งที่คาดการณ์ได้ยาก แต่สามารถป้องกันและกู้คืนได้ อย่างมีประสิทธิภาพ ทำให้ธุรกิจหรือกิจกรรมด้านไอทียังสามารถดำเนินต่อไปได้ หรือหากเกิดขัดข้องจะใช้เวลาสั้นที่สุดเพื่อที่จะให้ระบบกลับคืนสู่ปกติ บทความนี้ขอนำเสนอ แนวคิดขั้นพื้นฐานในการวางแผนเพื่อกู้คืนระบบให้รู้จักวิธีการรับมือและจัดการแก้ปัญหาหลังเกิดภัยพิบัติ
|
ภาพที่ 1 ภัยพิบัติที่เกิดขึ้นกับอุปกรณ์จัดเก็บข้อมูล |
ภาพที่ 2 ภัยพิ |

 บัติที่เกิดขึ้นกับคลังข้อมูลขนาดใหญ่
บัติที่เกิดขึ้นกับคลังข้อมูลขนาดใหญ่
เหตุใดจึงต้องมี Disaster Recovery
Disaster Recovery เป็นสิ่งจำเป็นสำหรับองค์กรด้วยเหตุผลดังนี้
- ช่วยให้สามารถกู้คืนระบบและการทำงานกลับคืนสู่ปกติ
- ช่วยลดผลกระทบความเสียหายต่อธุรกิจการงานขององค์กร
- ช่วยลดโอกาสที่จะเกิดภัยพิบัติประเภทต่างๆในอนาคต
ประเภทของภัยพิบัติ
ภัยพิบัติสามารถเกิดขึ้นได้หลายแบบ ทั้งที่เกิดขึ้นโดยธรรมชาติ และเกิดขึ้นโดยน้ำมือมนุษย์ ซึ่งมักเป็นผลมาจากความประมาท รวมทั้งปัญหาที่เกี่ยวกับความผิดพลาดของอุปกรณ์ อย่างไรก็ดี เราสามารถแบ่งประเภทของภัยพิบัติ ได้ดังนี้
- ภัยพิบัติจากธรรมชาติ
- ภัยพิบัติจากน้ำมือมนุษย์
- ความล้มเหลวในการทำงานของระบบคอมพิวเตอร์
- การคุกคามระบบคอมพิวเตอร์ที่มาจากภายนอก
- พฤติกรรมที่ไม่ชอบ หรือผิดปกติของเจ้าพนักงานในองค์กร
- ความผิดพลาดจากการปฏิบัติงานของเจ้าหน้าที่
- ความผิดพลาดจากการบริหารจัดการ Configuration
- การบริหารระบบ IT ที่ผิดพลาด
- ข้อมูลรั่วไหลหรือสูญหาย
- ไฟดับหรืออุปกรณ์เสียหาย
- ข้อมูลเสียหายจากไวรัส
การเลือกกลไกการกู้คืนระบบ
กลไกหรือวิธีการกู้คืนระบบจำเป็นต้อง ขึ้นอยู่กับสิ่งต่อไปนี้
- ข้อมูลที่ได้รับ การบำรุงรักษา และค่าใช้จ่ายในการปฏิบัติงาน
- งบประมาณการกู้คืนระบบขององค์กร
- ช่วงเวลาที่ใช้ไปกับการกู้คืนระบบ
- ความพร้อมของบุคคลากรเพื่อปฏิบัติงาน และการจัดการ
- ความพร้อมและ Solution จาก Third Party
การจัดตั้งทีมงานกู้คืนระบบ
บทบาทและความรับผิดชอบของทีมงานกู้คืนระบบได้แก่
- พัฒนาและใช้งาน ตลอดจนเฝ้าดู การปฏิบัติงานภายใต้แผนงานกู้คืนระบบที่เหมาะสม หลังจากวิเคราะห์จุดประสงค์ทางธุรกิจ และภัยคุกคามต่อองค์กร
- บริหารจัดการเกี่ยวกับการแจ้งเตือน และสั่งการไปยังบุคคลากรที่เกี่ยวข้อง รวมทั้ง Third Party เกี่ยวกับ ภัยพิบัติที่เกิดขึ้น
- ริเริ่มให้มีการดำเนินการใช้งานกระบวนการกู้คืนระบบ
- เฝ้าดูและดำเนินการตามแผนงานกู้คืนระบบ และประเมินผลการดำเนินงาน
- ดำเนินการทำให้ระบบกลับคืนสู่ปกติ
- ปรับแต่งและอัพเดทแผนงานกู้คืนระบบ โดยใช้บทเรียนจากภัยพิบัติที่ผ่านมา
- ยกระดับความพร้อมในการกู้คืนระบบขององค์กร โดยการจัดให้มีการทดสอบระบบกู้คืน และการวิเคราะห์ความเสี่ยง และภยันตรายต่างๆ
- จัดสร้างความตระหนักรู้ ให้แก่ผู้ที่เกี่ยวข้องในองค์กร โดยจัดให้มีการอบรมเกี่ยวกับแผนงานและวิธีการกู้คืนระบบ
ข้อพิจารณาการจัดตั้งทีมกู้คืนระบบ
- กำหนดให้มีบทบาทและความรับผิดชอบ สำหรับสมาชิกทีมงานที่ชัดเจน และมีการสื่อสารกันโดยตลอด
- โครงสร้างของทีมงานจะต้องดูเรียบง่าย และเป็นที่เข้าใจ
- สมาชิกทีมงานจะต้องมีทักษะและมีเครื่องมือที่พร้อม
เฟสของการกู้คืนระบบ
การกู้คืนระบบที่มีประสิทธิภาพ จำเป็นต้องมีลำดับขั้นตอนโดยสามารถกำหนดเป็นเฟสของการทำงานดังนี้
- Activation Phase
- ประกาศแจ้งเตือนแก่ผู้ที่เกี่ยวข้องและผู้ที่มีส่วนได้ส่วนเสีย กับกระบวนการกู้คืนระบบ
- ประเมินความเสียหายเพื่อกำหนดระดับของความเร่งด่วนในการกู้คืนระบบ
- กระตุ้นให้กระบวนการกู้คืนระบบเกิดขึ้น
- Notification Phase
ข่าวสารการแจ้งเตือนมีดังนี้
- ธรรมชาติของภัยพิบัติและความเสียหายที่อาจเกิดขึ้น
- ความสูญเสียชีวิต การบาดเจ็บ และความเสียหายที่มีต่อโครงสร้าง
- รายละเอียดที่จะตอบสนองในครั้งแรก
- การประมาณเวลาที่จะใช้ในการกู้คืนระบบ
- ข้อมูลข่าวสารเกี่ยวกับแผนงานโดยสรุป ข้อมูลจากที่ประชุม และข้อปฏิบัติในการตอบสนองต่อภัยพิบัติ
- การดำเนินการใดๆที่จะช่วยลดผลกระทบต่อการสูญเสียชีวิต และทรัพยสิน
- ข่าวสารและข้อแนะนำเกี่ยวกับสถานที่พักพิง หรือที่ทำงานชั่วคราว
- ข่าวสารเกี่ยวกับบุคคลหรือหน่วยงานที่จะต้องติดต่อด้วย หากเกิดภัยพิบัติ
- Damage Assessment Phase
กระบวนการประเมินความเสียหายและผลลัพธ์ที่เกิดหลังภัยพิบัติขึ้นอยู่กับปัจจัยดังนี้
- ธรรมชาติและสาเหตุของภัยพิบัติ
- ระบบและการปฏิบัติงานในยามวิกฤติที่ได้รับผลกระทบโดยภัยพิบัติ
- ความเป็นไปได้ของความเสียหายที่เกิดขึ้นต่อเนื่อง
- ธรรมชาติของความสูญเสียที่จะมีต่อโครงสร้างที่สำคัญ
- ช่วงเวลาที่คาดหวังว่าจะกู้คืนจากระบบที่ได้รับผลกระทบรวมทั้งการปฏิบัติงาน
แนวทางการตัดสินใจในการดำเนินแผนงานกู้คืนระบบ
- Execution Phase
ต่อไปนี้เป็นแนวทางที่สำคัญสำหรับเฟสนี้
- การจัดลำดับความสำคัญเกี่ยวกับกิจกรรมกู้คืนระบบ : เพื่อให้แน่ใจว่าสินทรัพย์ที่มีความสำคัญ รวมทั้งการปฏิบัติงานได้รับการกู้คืนก่อนอื่น
- กระบวนการกู้คืน : แนวทางการกู้คืนระบบที่ดีเป็นสิ่งสำคัญต่อการปฏิบัติงาน ทีมงานจะต้องตระหนักถึงลำดับการทำงานในกระบวนการกู้คืนระบบ ภายใต้สถานการณ์ต่างๆ
- Reconstitution Phase
- ในเฟสนี้ ระบบและปฏิบัติการที่ได้รับผลกระทบ จะถูกเรียกคืนสู่ภาวะปกติ ระบบใดที่ไม่สามารถเรียกคืน จะถูกแทนที่ด้วยระบบใหม่ ทีมงานจะต้องทดสอบให้แน่ใจว่า ระบบที่ผ่านการกู้คืนจะต้องไม่กลับมาสู่ความล้มเหลวอีก ก่อนที่จะนำไปติดตั้งที่เดิม ในเฟสนี้ครอบคลุมการทดสอบการปฏิบัติงานเป็นระยะๆ
จุดประสงค์ของการกู้คืนระบบ
ต่อไปนี้เป็นจุดประสงค์ของการกู้คืนระบบ ซึ่งมีอยู่ 3 ประการ
- Short-Term Recovery Objective : หลังจากภัยพิบัติ ในช่วง 2-3 ชั่วโมงหมดไปกับกู้คืน สิ่งอำนวยความสะดวกและโครงสร้าง
- Medium-Term Recovery Objectives : ในช่วงสัปดาห์แรกหลังจากเกิดภัยพิบัติ เป้าหมายหลักคือการเรียกคืน งานที่เป็นตัวหลักสำคัญที่ส่งผลกระทบต่อการดำเนินงานทางธุรกิจขององค์กร
- Long-Term Recovery Projects : จุดประสงค์คือการเรียกคืน ระบบที่เป็นเงื่อนไขก่อนเกิดภัยพิบัติ และจัดทำแผนงานตรวจสอบการทำงานหลังกู้คืน เพื่อให้แน่ใจว่าสามารถทำงานได้ในระยะยาว
Disaster Recovery Roles and Responsibilities
Operations Recovery Director
- ป้องปรามและป้องกัน มิให้เกิดวินาศภัย
- ตรวจสอบและอนุมัติแผนงานกู้คืนระบบ
- ดูแลรักษา กระบวนการ DRP (ควบคุมดูแล และบังคับใช้ ให้เป็นไปตามแผนงาน)
- ดำเนินการฝึกอบรมให้ใช้แผนงาน DRP
- มีอำนาจ หรือให้อำนาจแก่ผู้เกี่ยวข้องในการทดสอบกระบวนการ DRP
- ในช่วงของการจะกู้คืนระบบ จะทำหน้าที่ประกาศเหตุการณ์วินาศภัย
- กำหนดกลยุทธ์ที่เหมาะสม เพื่อนำไปใช้งานกู้ระบบ หากมีกลยุทธ์การรับมือมากกว่าหนึ่งแบบ
- มีอำนาจที่จะอำนวยความสะดวกแก่ทีมปฏิบัติงานกู้คืนระบบ
- จัดให้มีการเฝ้าดู ตลอดกระบวนการกู้คืนระบบ
- ติดตามและอัพเดทข้อมูลเกี่ยวกับสถานะของการกู้คืนระบบ แก่ฝ่ายปริหารระดับอาวุโส
- ประสานงานเกี่ยวกับการให้ข้อมูลข่าวสารสถานะการกู้คืนระบบแก่แผนกต่างๆที่เกี่ยวข้อง
ผู้จัดการฝ่ายปฏิบัติการและทีมกู้คืนระบบ
- จัดให้มีการป้องกันระบบ
- พัฒนาและดูแลรักษา ตลอดจนอัพเดท
- คัดเลือกบุคคลากรในทีม
- มอบหมายงานบางส่วนใน DRP แก่สมาชิกในทีมงานเป็นรายบุคคล
- ประสานงานด้านการวางแผนเพื่อทดสอบ
- ดำเนินการอบรมทีมงาน DRP เกี่ยวกับแผนงานและวิธีการเชิงปฏิบัติ
- ในช่วงของการเกิดเหตุการณ์ จะเป็นที่อนุมัติให้ดำเนินการกู้คืนระบบ
- ประกาศแจ้งแก่หัวหน้าทีม DRP หรือส่วนที่เกี่ยวข้อง ให้ดำเนินการกู้คืนระบบ
- วิเคราะห์ระดับความรุนแรงของปัญหา
- ประสานและรับรายงานสรุปจากเกี่ยวกับความเสียหายจากสมาชิกต่างๆในทีมงาน
- แจ้งข่าวสารแก่ฝ่ายจัดการขององค์กร เกี่ยวกับระดับความรุนแรงของปัญหาที่เกิดขึ้น
- ประสานงานกับทุกคนในทีม
- เรียกดูข้อมูลสำรองจาก Site ที่อยู่ไกลออกไป รวมทั้งเอกสาร และทรัพยากรที่เกี่ยวข้องจากทีมเทคนิคของแผนกไอที
- มีอำนาจอนุมัติให้จัดซื้อทรัพยากรที่จำเป็นเพิ่มเติมในการกู้คืนระบบ
- รายงานความคืบหน้าเกี่ยวกับสถานะการกู้คืนระบบไปยังผู้อำนวยการหรือฝ่ายจัดการกู้คืนระบบ
- ประสานงานเกี่ยวกับการให้ข้อมูลข่าวสารสถานะการกู้คืนระบบแก่แผนกต่างๆที่เกี่ยวข้อง
Facility Recovery Team
- เตรียมสถานที่สำหรับสำรองข้อมูล และระบบ
- เตรียมอุปกรณ์ด้าน Hardware และ Software ที่จำเป็น ต่อการสำรองข้อมูล
- จัดสร้างแผนปฏิบัติการและวิธีการกู้คืนระบบสำหรับ Site งานสำรอง
- ดำเนินการซ่อมแซม และทำให้ทุกอย่างใน Site งานหลักกลับคืนสู่ปกติ โดยเฉพาะสิ่งอำนวยความสะดวก
ทีมงานกู้คืนระบบเครือข่าย
- ติดตั้งอุปกรณ์ระบบเครือข่ายที่ Site งานสำรอง
- เมื่อเกิดปัญหา จะทำหน้าที่เชื่อมต่อเครือข่ายที่กำลังมีปัญหาบน Site งานหลักไปยัง Site งานสำรอง
- ดำเนินการกู้คืนระบบเครือข่ายที่กำลังมีปัญหาใน Site งานหลัก
ทีมงานกู้คืนเครื่องมือและอุปกรณ์ไอที
- ดูแลรักษารายการของอุปกรณ์ที่ต้องการใช้ในกระบวนการกู้คืนระบบไอที
- เมื่อเกิดเหตุการณ์ขึ้น จะทำหน้าที่ติดตั้งอุปกรณ์ทาง Hardware ของไอที
- เรียกคืนข้อมูลและระบบจาก Site งานสำรองที่อยู่ไกลออกไป
ทีมงานกู้คืน Platform
ช่วงก่อนเกิดภัยพิบัติ
- ดูแลรักษารายการอุปกรณ์ที่เกี่ยวข้องกับกระบวนการกู้คืนระบบ
ภายหลังภัยพิบัติ
- ติดตั้งอุปกรณ์ Hardware
- เรียกคืนข้อมูลและระบบจาก ข้อมูลที่ได้ทำสำเนาไว้จากที่ไกล
ทีมงานกู้คืน Application
ช่วงก่อนเกิดภัยพิบัติ
- ทดสอบดู Application เพื่อหาช่องโหว่
ภายหลังเกิดภัยพิบัติ
- เรียกคืนฐานข้อมูล
- เรียกหา Application ที่เจาะจงกับงานในระบบ
ทีมงานประเมินความเสียหายและช่วยเหลือ
- มีความเข้าใจในบทบาทหน้าที่ของ DR
- ทำงานไกล้ชิดกับทีมงานกู้คืนระบบ เพื่อลดความเสียหายที่อาจเกิดขึ้นใน Data Center
- ดำเนินการฝึกอบรมแก่ทีมงานกู้คืนระบบในการเตรียมการรับมือกับเหตุฉุกเฉิน
- เข้าไปมีส่วนร่วมในการทดสอบ DRP
- ในช่วงเกิดเหตุการณ์ให้เข้าไปดู และระบุขนาดความเสียหาย
- ประเมินความต้องการเกี่ยวกับการรักษาความปลอดภัยทางกายภาพ
- ประมาณการณ์เกี่ยวกับเวลา กู้คืนสอดคล้องกับความเสียหายที่ประเมินได้
- สำรวจดูว่าอุปกรณ์ต่างๆรวมทั้ง Hardware อื่นๆที่เกี่ยวข้อง ส่วนใดที่สามารถซ่อมแซมได้
- อธิบายให้กับทีมงานกู้คืนระบบเกี่ยวกับความเสียหายที่อาจเกิดขึ้นต่อเนื่อง รวมทั้งการประมาณการณ์เกี่ยวกับเวลาที่ใช้ไปในการกู้คืนระบบ รวมทั้งความปลอดภัยทางกายภาพ ตลอดจนระบุอุปกรณ์ที่สามารถซ่อมแซมได้
- ดูแลรักษาอุปกรณ์ทาง Hardware ที่สามารถซ่อมแซมได้รวมทั้งบันทึกต่างๆในอุปกรณ์
- ประสานงานกับผู้ค้าอุปกรณ์รวมทั้ง Supplier เพื่อดำเนินการส่งซ่อม หรือเปลี่ยนอุปกรณ์ใหม่
- ประสานงานให้มีการจัดส่งอุปกรณ์ช่วยเหลือเพื่อกู้คืนระบบไปที่ Site งานที่กำลังมีปัญหา
- ให้การสนับสนุนในการจัดระเบียบ และทำความสะอาดสถานที่ติดตั้งอุปกรณ์ไอที หลังจากเกิดปัญหา
ทีมงานดูแลความปลอดภัยทางกายภาพ
ก่อนเกิดภัยพิบัติ
- มีความเข้าใจในบทบาท และความรับผิดชอบของการกู้คืนระบบ
- ทำงานไกล้ชิดกับทีมงานกู้คืนระบบ เพื่อให้แน่ใจว่าทรัพยากรไอที รวมทั้งระบบมีความปลอดภัยทางกายภาพ
- ดำเนินการฝึกอบรมแก่พนักงานที่เกี่ยวข้อง
- เข้าร่วมในการทดสอบ DRP หากต้องการ
- ดูแลรักษารายการของบุคคลากรที่มีสิทธิ์เข้ามาทำงานใน Site งานที่เกิดปัญหา รวมทั้ง Site งานที่ใช้กู้คืนระบบ
หลังเกิดภัยพิบัติ
- ประเมินความเสียหายที่ Site งานที่กำลังเกิดปัญหา
- ป้องกัน Data Center จากการเข้าถึงโดยบุคคลที่ไม่เกี่ยวข้อง
- จัดทำหมายกำหนดการในการส่งถ่ายแฟ้มข้อมูล หรือรายงาน และอุปกรณ์อย่างปลอดภัย
- เข้าไปมีส่วนร่วมในการสืบค้นที่มาของปัญหาใน Site งานที่กำลังเหตุการณ์
ทีมงานสื่อสาร
ก่อนเกิดภัยพิบัติ
- มีความเข้าใจในบทบาทและความรับผิดชอบของ DR
- ทำงานใกล้ชิดกับทีมงานกู้คืนระบบ เพื่อให้แน่ใจว่า ระบบและทรัพยากรไอทีมีความปลอดภัยทางกายภาพ
- ดำเนินการฝึกอบรมให้แก่พนักงานในองค์กร หรือผู้ที่เกี่ยวข้องกับไอที
- มีส่วนร่วมในการทดสอบแผนงานกู้คืนระบบ หากต้องการ
- จัดตั้งและดูแลรักษาอุปกรณ์สื่อสารที่ Site งานสำรอง
หลังเกิดภัยพิบัติ
- ประเมินความต้องการของอุปกรณ์สื่อสารโดยการประสานงานกับทีมงานอื่นๆ
- วางแผนและประสานงาน รวมทั้งติดตั้งอุปกรณ์สื่อสารที่ Site งานสำรอง ซึ่งเป็น Site งานที่ใช้กู้คืนระบบ
- วางแผนประสานงานและติดตั้ง อุปกรณืเครือข่าย และเดินสายสัญญาณที่ Site งานสำรอง
ทีมงานติดตั้ง Hardware
ก่อนเกิดภัยพิบัติ
- มีความเข้าใจในบทบาทและความรับผิดชอบในการกู้คืนระบบ
- ประสานงานกับทีมงาน DR เพื่อลดผลกระทบจากความเสียหายใน Data Center
- ดำเนินการฝึกอบรมแก่เจ้าพนักงานในองค์กร
- เข้าร่วมในการทดสอบแผนงานกู้คืนระบบ
- ดูแลรักษาระบบที่ใช้งานอยู่ในปัจจุบัน รวมทั้งคอนฟิกกูเรชั่นของระบบ LAN จาก Site งานสำรอง
หลังเกิดภัยพิบัติ
- ดำเนินการตรวจสอบความต้องการของอุปกรณ์ Hardware ที่ Site งานสำรอง
- ตรวจสอบสถานที่ซึ่งเป็น Site งานสำรอง เพื่อดูว่าต้องการพื้นที่ติดตั้งอุปกรณ์เท่าไร?
- ประสานงานในด้านการขนส่งอุปกรณ์ที่ต้องซ่อมแซม ไปยัง Site สำรอง
- รายงานอุปกรณ์ที่ต้องซ่อมแซม รวมทั้งอุปกรณ์ใหม่ๆทดแทนแก่ผู้จัดการไอที หรือฝ่ายบริหารที่เกี่ยวข้อง
- วางแผนและติดตั้ง Hardware ที่ Site งานสำรอง
- วางแผน ดำเนินการขนส่งรวมทั้งติดตั้งอุปกรณ์ทาง Hardware ณ สถานที่สำรองเมื่อพร้อม
ทีมงานปฏิบัติงานด้านไอที
ก่อนเกิดภัยพิบัติ
- มีความเข้าใจในบทบาทและความรับผิดชอบในการกู้คืนระบบ
- ทำงานไกล้ชิดกับทีมงานกู้คืนระบบ เพื่อให้แน่ใจว่า ระบบและทรัพยากรไอทีมีความปลอดภัยทางกายภาพ
- ดำเนินการฝึกอบรมให้กับพนักงานเพื่อให้มีความพร้อมต่อการรับมือเหตุฉุกเฉิน
- ตรวจสอบและดำเนินการเพื่อให้แน่ใจว่า การสำรองหรือการทำสำเนาข้อมูลเป็นไปตามหมายกำหนดการ
- ตรวจสอบให้แน่ใจว่าข้อมูลที่ได้จัดทำเป็นสำเนาได้ถูกส่งไปจัดเก็บที่ Site งานสำรอง
- เข้าร่วมในการทดสอบแผนงาน DRP เมื่อต้องการ
หลังจากภัยพิบัติ
- สนับสนุน ทีมงานเทคนิคไอที เมื่อต้องการ
- จัดส่ง และรับข้อมูลข่าวสารจากอุปกรณ์จัดเก็บข้อมูล
- ตรวจสอบให้แน่ใจว่า เทปสำเนาข้อมูลได้ถูกจัดส่งไปที่ Site งานสำรอง
- ตรวจสอบระบบรักษาความปลอดภัยของเครือข่าย LAN ที่ Site งานสำรอง
- ประสานงานในด้านการส่งถ่ายข้อมูลข่าวสาร รวมทั้งทรัพยากร และบุคคลากรไปยัง Site งานสำรอง
ทีมงานเทคนิคด้านไอที
ก่อนเกิดภัยพิบัติ
- มีความเข้าใจในบทบาทและความรับผิดชอบในการกู้คืนระบบ
- ประสานงานกับทีมงาน DR เพื่อลดผลกระทบจากความเสียหายใน Data Center
- ดำเนินการฝึกอบรมแก่เจ้าพนักงานในองค์กร
- เข้าร่วมในการทดสอบระบบ DRP เมื่อต้องการ
หลังเกิดภัยพิบัติ
- ดำเนินการเรียกคืนข้อมูลข่าวสารจากสื่อที่ใช้ทำสำเนาข้อมูล เช่น เทป หรือสื่ออื่นๆ
- ดำเนินการทำสำเนาข้อมูลที่ Site งานสำรองที่อยู่ไกลออกไป
- ทดสอบการทำงานของระบบปฏิบัติการ
- ดำเนินการดัดแปลงการจัดคอนฟิกกูเรชั่นของระบบ LAN เพื่อให้สามารถเชื่อมต่อกับ Site งานสำรอง
ทีมงานบริหารจัดการ
ก่อนเกิดภัยพิบัติ
- มีความเข้าใจในบทบาทและความรับผิดชอบในการกู้คืนระบบ
- ดำเนินการฝึกอบรมแก่พนักงาน
- ตรวจสอบให้แน่ใจว่า มีงบประมาณมากเพียงพอ พร้อมสำหรับการะบวนการกู้คืนระบบหรือไม่
- ประเมินหาระบบสื่อสารสำรองในกรณีที่ระบบโทรศัพท์ไม่สามารถใช้งานได้ตามปกติ
- เข้าร่วมในการทดสอบ DRP เมื่อต้องการ
หลังเกิดภัยพิบัติ
- จัดให้มีการอำนวยความสะดวกต่อการเดินทางของทีมงาน
- อนุมัติให้มีการจัดซื้ออุปกรณ์ที่เกี่ยวข้องกับกระบวนการกู้คืนระบบ
ขั้นตอนในการวางแผนกู้คืนระบบ
เมื่อดำเนินการวางแผนกู้คืนระบบ องค์กรจะต้องดำเนินการตามขั้นตอนดังนี้
- พิสูจน์ทราบและประเมินความเสี่ยง
- จัดลำดับความสำคัญความสำคัญของกระบวนการธุรกิจ
- จัดลำดับความสำคัญในการให้บริการทางเทคโนโลยี
- กำหนดกลยุทธ์ในการกู้คืนระบบ
- จัดระบบรักษาความปลอดภัยให้กับสิ่งอำนวยความสะดวก
- คัดเลือก Site งานสำรองที่เหมาะสม
- ใช้ระบบทดแทน
- จัดทำเอกสารและวางแผนงาน
- ทดสอบแผนงาน
- กำหนดให้มีการปรับปรุงแผนการกู้คืน
การจัดทำโปรไฟล์ (Profiles)
Profiles เป็นส่วนหนึ่งของการวางแผนกู้คืนระบบ ดังนั้นจึงจำเป็นต้องมีการจัดทำ Profiles สำหรับการปฏิบัติงาน รวมทั้ง Application และบัญชีรายการสิ่งของที่เกี่ยวข้องกับการกู้คืนระบบ
Operation Profiles
เป็นข้อมูลเกี่ยวกับ แผนการปฏิบัติการ ระบบการทำงาน องค์ประกอบที่ช่วยในการตัดสินใจ ผู้รับผิดชอบในแต่ละส่วน และขอบเขตการรับผิดชอบ รวมทั้งขอบเขตของงาน เป็นต้น
Application Profiles
เพื่อให้การบริหารจัดการกู้คืนระบบมีประสิทธิภาพ จำเป็นอย่างยิ่งที่จะจัดทำ Profiles สำหรับระบบทั้งหมด รวมทั้งระบบที่มีลำดับความสำคัญสูงสุด และรองลงมา และเมื่อมีการจัดลำดับความสำคัญ องค์กรควรที่จะรวมเอา RPO และ RTO เข้าไปไว้ใน Application Profile ด้วย ดูตัวอย่างตามตาราง xxx เพื่อจุดประสงค์ให้สามารถติดตามดูลำดับความสำคัญของระบบที่จะต้องดูแล
Inventory Profile
องค์กรควรจัดเก็บบัญชีรายการเกี่ยวกับอุปกรณ์ หรือสิ่งที่เกี่ยวข้องกับการให้บริการไอที รวมทั้งอุปกรณ์ที่เป็นอะไหล่ หรือสามารถทดแทนกันได้ หากเกิดปัญหาไม่สามารถทำงานได้ตามปกติ แสดงแบบฟอร์มที่ใช้บันทึกรายการสิ่งของ ทดแทนเพื่อใช้เปลี่ยนในกรณีที่อุปกรณ์หลักไม่สามารถใช้งานได้ รวมทั้งรายการสิ่งของหลักที่กำลังทำงานให้บริการระบบไอทีในปัจจุบัน
วิธีการประเมินความเสียหาย
กระบวนการประเมินความเสียหาย จะต้องประกอบด้วยขั้นตอนต่อไปนี้
- ระบุสาเหตุที่ทำให้การทำงานของระบบขัดข้อง
- ประมาณขนาดพื้นที่ๆกำลังเกิดปัญหา
- กะจำนวนเวลาที่จะใช้ไปในการตรวจซ่อมให้กลับสู่สภาวะปกติ
- ประเมินดูว่าอุปกรณ์ในที่เกิดเหตุจะสามารถทำงานต่อไปได้อีกนานเท่าใด และให้คิดถึงสิ่งที่จะมาทดแทนที่อยู่ในคลังเก็บของ
กระบวนการกู้คืน
องค์กรควรมีข้อมูลเกี่ยวกับวิธีการกู้คืนระบบทั้งหมดที่ Site งานสำรอง ข้อมูลเกี่ยวกับวิธีการทำงานนี้ควรครอบคลุม รายละเอียดของงาน ที่ฝ่ายปฏิบัติการกู้คืนระบบจะต้องปฏิบัติตามเพื่อกู้คืนระบบ ตลอดจน Application และโครงสร้างของระบบที่เกี่ยวข้อง รวมทั้ง ระบบ Hardware และการติดตั้ง Software
ความต้องการของ Site งานสำรอง
เมื่อมีการเลือก Site งานสำรองที่เหมาะสม ต้องแน่ใจว่ามีทรัพยากรที่จำเป็นและเพียงพอต่อการทำให้การปฏิบัติงาน ดำเนินต่อไปได้ ทรัพยากรมีดังนี้
- ระยะทางหรือความห่างของสถานที่ๆติดตั้งอุปกรณ์
- ระยะความห่างของ Disaster Recovery Site
- สภาพพื้นที่
- ความเสี่ยงต่อภัยธรรมชาติ
- พื้นที่ว่างสำหรับทำงาน
- ทางเข้าสู่พื้นที่สำหรับทำงาน
- ห้องและพื้นที่ว่างสำหรับพนักงานแต่ละคน
- ห้องและพื้นที่ว่างสำหรับจัดประชุม
- พื้นที่จัดเก็บอุปกรณ์ และเอกสารต่างๆ
- พื้นที่จัดตั้งอุปกรณ์สำนักงาน
- ตรวจสอบให้แน่ใจว่า มีระบบบริการที่ทำให้ธุรกิจสามารถดำเนินการต่อไปได้ เช่นระบบโทรศัพท์ การ Access Internet และเครื่อง Fax
- เครื่องใช้สำนักงานทั่วไป
- เครื่องคอมพิวเตอร์
- จำนวนของเครื่องคอมพิวเตอร์ที่จำเป็นต่อการรัน Application ที่สำคัญ
- ผู้ที่เกี่ยวข้องกับการติดตั้ง Application
- ความพร้อมที่จะใช้งานระบบ LAN
- จำนวนของเครื่องพิมพ์ที่พอเหมาะต่อการทำงาน
- การขนส่งหรือคมนาคม
- Supporting Services
- ความปลอดภัยทางกายภาพ
- Environment Support เช่น HVAC แสงสว่าง
|
ภาพที่ 3 การจัดตั้ง สถานที่ประมวลผลและจัดเก็บข้อมูลสำรอง |
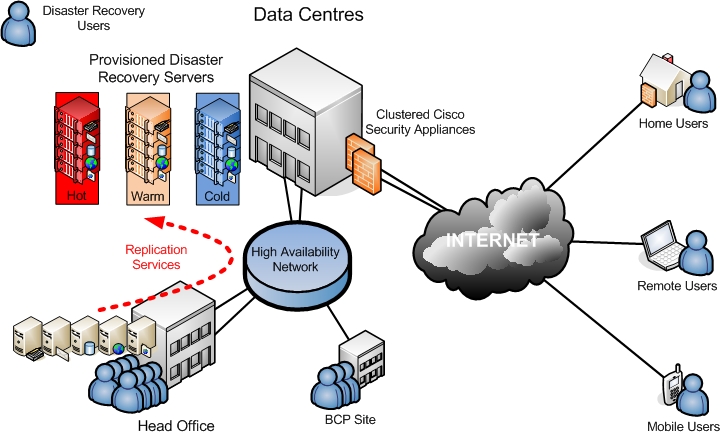
ข้อพิจารณาการวางแผนทางเทคนิคที่อาจเกิดขึ้นได้
ระบบ Desktop Computer และอุปกรณ์คอมพิวเตอร์พกพา
- ดำเนินการทำสำเนาข้อมูล หลังจากใช้งาน และเก็บไว้นอกพื้นที่
- กำหนดให้มีการทำสำเนาบนคอมพิวเตอร์แต่ละเครื่อง
- กำหนดแนวทางการบันทึกและทำสำเนาข้อมูลบนเครื่องคอมพิวเตอร์
- กำหนดเครื่องคอมพิวเตอร์ รวมทั้ง Software และอุปกรณ์พ่วงต่อที่เกี่ยวข้องกับการกู้คืนระบบ
- จัดทำเอกสาร เกี่ยวกับConfiguration ของระบบ และข้อมูลผู้ค้าอุปกรณ์
- ใช้ข้อมูลจากการวิเคราะห์ความเสี่ยง
เมื่อมีความต้องการเลือกสื่อเพื่อทำสำเนาข้อมูล พิจารณาดังนี้
- ความเข้ากันได้ของอุปกรณ์
- ขนาดความจุของอุปกรณ์จัดเก็บข้อมูล
- อายุการจัดเก็บข้อมูลของสื่อ
ตัวอย่างสื่อทำสำเนาเก็บข้อมูล
- Tape Drives
- อุปกรณ์จัดเก็บข้อมูลที่เคลื่อนย้ายได้
- Compact Disc
- Network Storage เช่น NAS
- Replication หรือ Synchronization กับอุปกรณ์จัดเก็บข้อมูล
- Internet Backup
Servers
- จัดทำสำเนาข้อมูลหลังใช้งาน และจัดเก็บไว้นอกพื้นที่
- กำหนดเครื่องคอมพิวเตอร์ รวมทั้ง Software และอุปกรณ์พ่วงต่อที่เกี่ยวข้องกับการกู้คืนระบบ
- จัดทำเอกสาร เกี่ยวกับConfiguration ของระบบ และข้อมูลผู้ค้าอุปกรณ์
- ประสานงานกับนโยบายการรักษาความปลอดภัย และการควบคุมความปลอดภัยของระบบ
- ใช้ข้อมูลจากการวิเคราะห์ความเสี่ยง
Hardware configuration: รวบรวมข้อมูลทุกอย่างเกี่ยวกับ Hardware บน Server รวมทั้ง
- แหล่งผลิต model และ serial number
- Firmware (BIOS/CMOS) versions
- จำนวนและชนิดของ CPUs
- ขนาดและชนิดของหน่วยความจำ
- จำนวน ชนิด รวมทั้ง Hardware configuration ของ network adaptors
- จำนวน ชนิด และ Hardware configuration ของ storage interfaces เช่น SCSI adaptors
- อุปกรณ์ Hardware ที่ติดตั้งจริงใน Server
- อุปกรณ์ต่อพ่วง ครอบคลุม model, version, และอื่นๆ
Operating system: รวบรวมรายละเอียดทุกอย่างเกี่ยวกับ ระบบปฏิบัติการ
- Version, release date, และ patch level ของ OS ที่ใช้
- ที่ติดตั้ง Patches รวมทั้ง Version ของ Patches
- ลำดับของการติดตั้ง
- ส่วนประกอบที่ติดตั้งด้วยกัน รวมทั้ง Version
- Boot configuration
- Recovery settings
ข้อมูลอื่นๆของ Server
- Resource configuration: Virtual memory, disk utilization settings, memory utilization
- Network และ network services configuration: subnet mask, gateway, DNS server, directory server, และ time Server รวมทั้ง tuning settings, เช่นจำนวนของ open connections ตลอดจน buffer allocation.
- Security configuration: event logging, system auditing, system-level access control configuration, patch download และ installation, ตลอดจน user account settings.
- System-level components: ชิ้นส่วนอื่นๆ ที่ติดตั้งในระดับ System level ได้แก่
- Firewall
- IDS และ IPS
- Anti-virus และ anti-malware อื่นๆ
- System management agents
Access management: ครอบคลุม
- User IDs, user ID และ password configuration
- Configurations ที่เกี่ยวข้องกับการจัดการกับ User แบบ รวมศูนย์ เช่น LDAP หรือ Active Directory
- ทรัพยากรที่ใช้แบ่งปันกัน เช่น Directory และ Resource อื่นๆที่ User สามารถ Access ผ่านเครือข่าย
พัฒนาขีดความสามารถที่จะติดตั้ง Server ใหม่
Change management: เป็นกระบวนการทางธุรกิจที่ เกี่ยวข้องการวิเคราะห์ รวมทั้งพัฒนา และอนุมัติให้มีการเปลี่ยนแปลง เป้าหมายคือ เปิดเผยความเสี่ยงและอื่นๆ ที่อาจทำให้ระบบมีปัญหา รวมทั้งพัฒนาวิธีการเปลี่ยนแปลงเพื่อลดความเสี่ยง ก่อนที่ปัญหาจะเกิดขึ้น
Configuration management: เป็นกระบวนการบันทึกการเปลี่ยนแปลงต่างๆที่เกิดขึ้น กับอุปกรณ์และระบบ โดยมีการจัดเก็บไว้ในส่วนจัดเก็บข้อมูลกลาง หรือที่เรียกว่า Configuration Management Database (CMD)
ข้อพิจารณาเกี่ยวกับการทำงานของ Server แบบ Distributed
- Interfaces:
- Latency
- Network considerations
ข้อพิจารณาเกี่ยวกับการป้องกันและกู้คืนระบบเครือข่าย
ส่วนประกอบที่เกี่ยวข้อง
- Data circuits and trunks
- Domain name service (DNS)
- Publicly routable network numbers
- Office telephone service
- Network Time Protocol (NTP)
- Firewalls
- Network security devices
- IDS และ IPS
- Spam filters
- Web proxies และ filters
- Load balancers
- Hardware encryption
- VLANs (virtual networks)
- DMZ (demilitarized zone) network segments
- อุปกรณ์เครือข่าย เช่น Server และอื่นๆ
- กระบวนการบริหารจัดการ เช่น Change Management และ Configuration Management
- Network architecture, routing, และ addressing
- Network management
ข้อมูลบน Server สามารถถูกทำสำเนาได้หลายวิธี
- Full Backup (Backup ทุก File ลงบนสื่อจัดเก็บข้อมูล)
- Incremental Backup (Backup เฉพาะ File ที่มีการเปลี่ยนแปลงหลังจากทำ Backup)
- Differential Backup (Backup ทุก File ใน Drive ที่มีการเพิ่มเติมหรือเปลี่ยนแปลง หลังจาก Full Backup)
- Redundant Array of Independent Disks (RAID)
กลยุทธ์การทำ Backup
- Backup ข้อมูลไปไว้ที่อื่น
- จัดทำหมายกำหนดการ Backup
- จัดให้มีการแจ้งเตือนเรื่องการ Backup
- กำหนด Security ให้เพียงพอ
- มีการทดสอบข้อมูลที่ Backup ตามปกติ
การทำสำเนาข้อมูลบน Cloud
ปัจจุบันท่านสามารถทำสำเนาข้อมูลบน Cloud ได้สะดวก โดยมีผู้ให้บริการหลายแห่งให้บริการตั้งแต่การบริการฟรีขนาด 2 GB จนถึงระดับความจุที่สูงขึ้นในราคาประหยัด
|
ภาพที่ 4 การใช้บริการ Cloud |
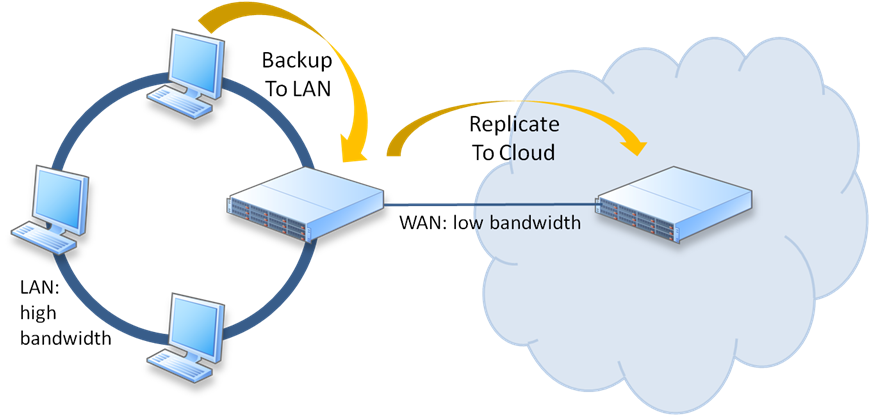
เหตุใดจึงควรใช้ Cloud Backup ?
มีเหตุผลหลายประการที่ควรใช้บริการสำรองข้อมูลจาก Cloud ได้แก่ มีความปลอดภัย สะดวก รวดเร็วและต้นทุนค่าใช้จ่ายที่ต่ำ
ผู้ให้บริการบางราย มีระบบทำสำเนาข้อมูลแบบออนไลน์ที่เรียกว่า StepUp Backup ซึ่งเป็นบริการที่คุณสามารถเก็บและเรียกคืนไฟล์ทั้งหมดของคุณในสภาพแวดล้อมที่ปลอดภัยนอกสถานที่โดยไม่ต้องลงทุนด้วยเงินทุนที่มากมาย ผู้ให้บริการพร้อมที่จะบริหารจัดการการติดตั้งและการบำรุงรักษาสำหรับคุณเพื่อให้คุณสามารถดำเนินการทางธุรกิจได้อย่างมีประสิทธิภาพ
StepUpBackup ใช้ในระดับเดียวกันของการรักษาความปลอดภัยที่ธนาคารชั้นนำของอุตสาหกรรมการเงินที่ใช้สำหรับธนาคารออนไลน์ที่ปลอดภัย ไฟล์ของคุณจะถูกเก็บไว้นอกสถานที่ในสองศูนย์ข้อมูลที่มิเรอร์ที่ตั้งอยู่บนฝั่งตรงข้าม แม้ว่า บริษัท ของคุณได้รับความเสียหายจากน้ำท่วมไฟไหม้ หรือถูกทำลาย คุณสามารถมั่นใจได้ว่าข้อมูลของคุณมีความปลอดภัย
1. การรักษาความปลอดภัย - ผู้ให้บริการหลายแห่งนำเสนอระบบรักษาความปลอดภัยข้อมูล ในระดับที่ใช้กับระบบการเงินของธนาคาร
2. ราคาไม่แพง – ด้วยราคาที่ประหยัดเมื่อเทียบกันกับการจัดซื้อและบำรุงรักษาอุปกรณ์จัดเก็บข้อมูล โดยคุณสามารถเลือกขนาดพื้นที่จัดเก็บข้อมูลได้ ตามความเหมาะสม
3. การเรียกคืนข้อมูลที่รวดเร็ว –ผู้ให้บริการบางแห่งมีบริการเรียกคืนข้อมูลที่รวดเร็วคืดเป็น 3 เท่าของปกติ
4. การสำรองข้อมูลระดับบล็อก – เมื่อไฟล์ได้รับการบันทึกครั้งเดียวซอฟต์แวร์ของผู้ให้บริการบางแห่งจะดำเนินการบันทึกเฉพาะข้อมูลใหม่ที่มีการเปลี่ยนแปลงในระดับของบล็อก
5. การจัดตารางเวลาที่มีความยืดหยุ่น – คุณสามารถจัดตั้งกำหนดการในการทำสำเนาข้อมูลได้ด้วยตนเอง เพื่อให้มีความยืดหยุ่นในการกำหนดเวลา การสำรองข้อมูลแต่ละชุดสามารถตั้งค่าให้ทำงานในเวลาที่ผู้ใช้กำหนดได้
Web Sites
- จัดทำเอกสารเกี่ยวกับ Configuration ด้าน Hardware และ Software
- จัดทำเอกสาร หากมีการเปลี่ยนแปลง ข้อมูลและโปรแกรมบน Web Sites
- ประสานงานกับนโยบายการรักษาความปลอดภัย และการควบคุมความปลอดภัยของระบบ
- ใช้ข้อมูลจากการวิเคราะห์ความเสี่ยง
ระบบ LAN
- วาดผังการเชื่อมต่อเครือข่าย
- ครอบคลุม ลักษณะการเดินสาย อุปกรณ์ที่เชื่อมต่อกัน
- Remote Access ที่ให้บริการโดย Server บน LAN
- จัดทำเอกสารเกี่ยวกับ Configuration ด้าน Hardware และ Software
- ประสานงานกับนโยบายการรักษาความปลอดภัย และการควบคุมความปลอดภัยของระบบ
- ใช้ข้อมูลจากการวิเคราะห์ความเสี่ยง
Wide Area Network (WAN)
- วาดผังการเชื่อมต่อบน WAN
- จัดทำเอกสารเกี่ยวกับ Configuration ด้าน Hardware และ Software
- ประสานงานกับนโยบายการรักษาความปลอดภัย และการควบคุมความปลอดภัยของระบบ
- ใช้ข้อมูลจากการวิเคราะห์ความเสี่ยง
- จัดทำ Communication Links แบบ Redundant
- จัดทำ การเชื่อมต่อกับ Network Service Provider (NSP) แบบ Redundant
- จัดทำ Redundant การเชื่อมต่อของอุปกรณ์ระบบเครือข่าย
การออกแบบ Disaster Recovery Planning
แนวคิดการออกแบบ
ในการออกแบบ Disaster Recovery หัวใจแห่งคำถามคือ
- อะไรบ้างที่จะต้องได้รับการป้องกัน (Services/Data) ?
- ความล้มเหลวใดที่ต้องเกี่ยวข้องกับ Disaster Recovery ?
- หน้าที่การทำงานที่จำเป็นใดสำหรับเหตุการณ์ที่มี Priority สูงสุด
- หน้าที่ใดที่จะต้องดำเนินการให้เร็วที่สุดเท่าที่จะทำได้
ความพร้อมของ Server
เพื่อที่จะรับมือกับ Disaster Recovery สำหรับ Server จะต้องรู้ข้อมูลต่อไปนี้
- ข้อมูลทางเทคนิค : เช่น ตำแหน่งที่ตั้งของสถานที่ติดตั้ง สถาปัตยกรรม ขีดความสามารถ และสัญญาเกี่ยวกับการบำรุงรักษา
- Application รวมทั้ง Infrastructure Services ใดที่เกี่ยวข้องกับ Business Service
- มี Solution แบบ Redundancy และ Failover ใดบ้างในระบบ ?
- มีแนวทางหรือกลยุทธ์เกี่ยวกับการทำสำเนาข้อมูลหรือไม่?
ความพร้อมของ Application
เพื่อที่จะรับมือกับ Disaster Recovery สำหรับ Application ควรมีข้อมูลดังนี้
- มี Server ใดบ้างที่เกี่ยวข้องกับ Application ที่ต้องการปกป้อง ?
- Application ใดที่มีความสำคัญต่อองค์กรธุรกิจ
- มี Application อื่นใดที่จำเป็น ต้องใช้สำหรับงาน Disaster Recovery นี้
ความพร้อมของ Site งานสำรอง
เพื่อที่จะรับมือกับ Disaster Recovery สำหรับ Site งานสำรอง ควรมีข้อมูลดังนี้
- Server ใดบ้างที่ติดตั้งใน Site งานสำรองนี้ ?
- มีระบบ High Availability ใด ติดตั้งใน Site สำรองแห่งนี้ ?
สถานะความเป็นเจ้าของ ของ Site สำรอง
- Site สำรองที่มีเจ้าของเพียงผู้เดียว : เหมาะสำหรับองค์กรขนาดใหญ่ที่มี Data Center หลายแห่ง โดย Site สำรองนี้เป็น Data Center ที่ถุกจัดตั้งเพื่อเป็น Site สำรอง และให้บริการกู้คืนระบบสำหรับ Site งานหลักอื่นๆ
- Site งานสำรองที่เป็นของ Third Party
ทรัพยากรที่ใช้ในการกู้คืนระบบ
มี 3 แบบ ได้แก่
- Shared System : ใช้ทรัพยากรที่มีอยู่แล้วทั้งหมด โดยมีการกระจาย Work Load ไปทั่วทั้ง 2 Site
- แบบ Hot Standby : เป็นทรัพยากรที่เตรียมสำรองไว้รอใช้งาน ในกรณีที่เกิดปัญหา
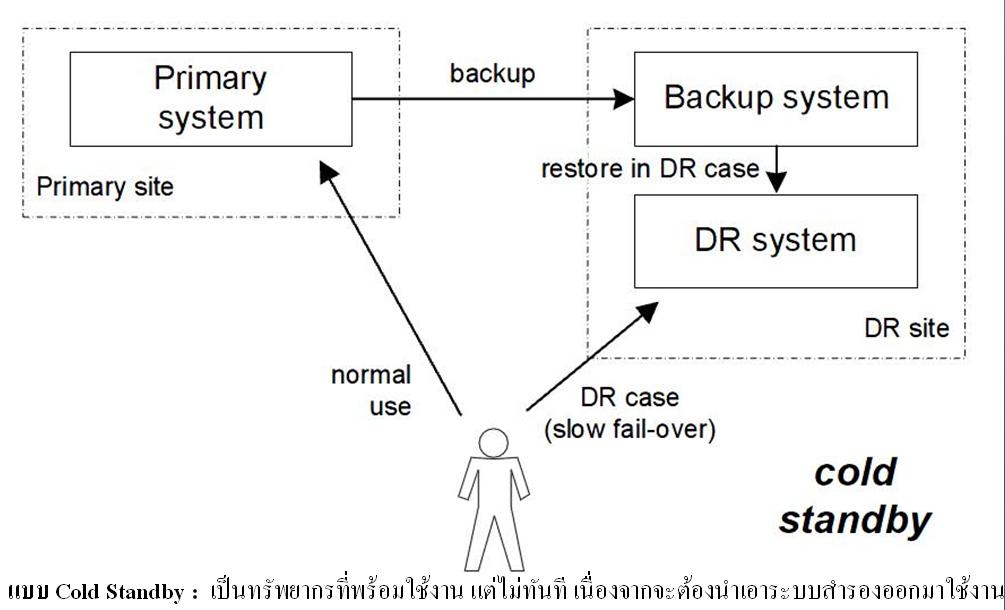
- แบบ Cold Standby : เป็นทรัพยากรที่พร้อมใช้งาน แต่ไม่ทันที เนื่องจากจะต้องนำเอาระบบสำรองออกมาใช้งาน
แบบที่ 1
ภาพที่ 5 แบบ Shared System
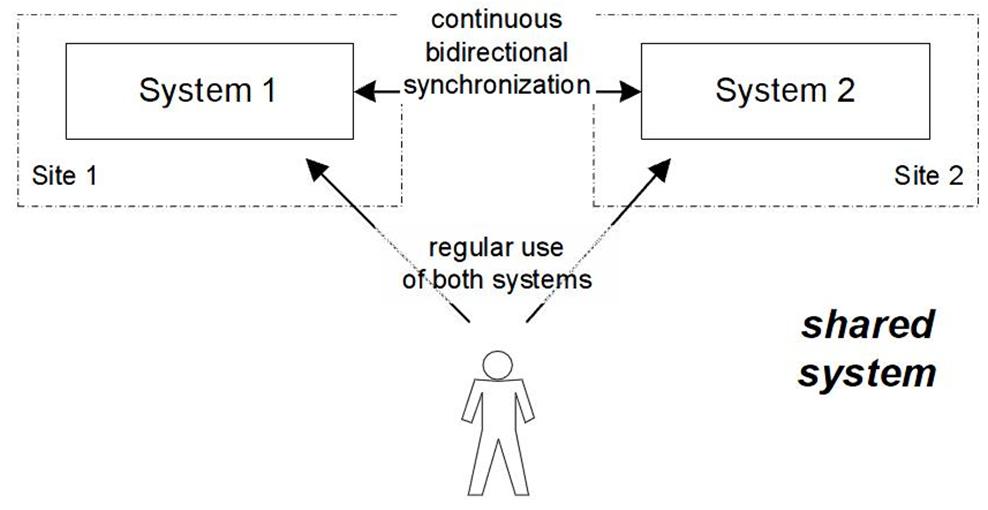
Shared System : ใช้ทรัพยากรที่มีอยู่แล้วทั้งหมด โดยมีการกระจาย Work Load ไปทั่วทั้ง 2 Site
แบบที่ 2
ภาพที่ 6 แบบ Hot Standby
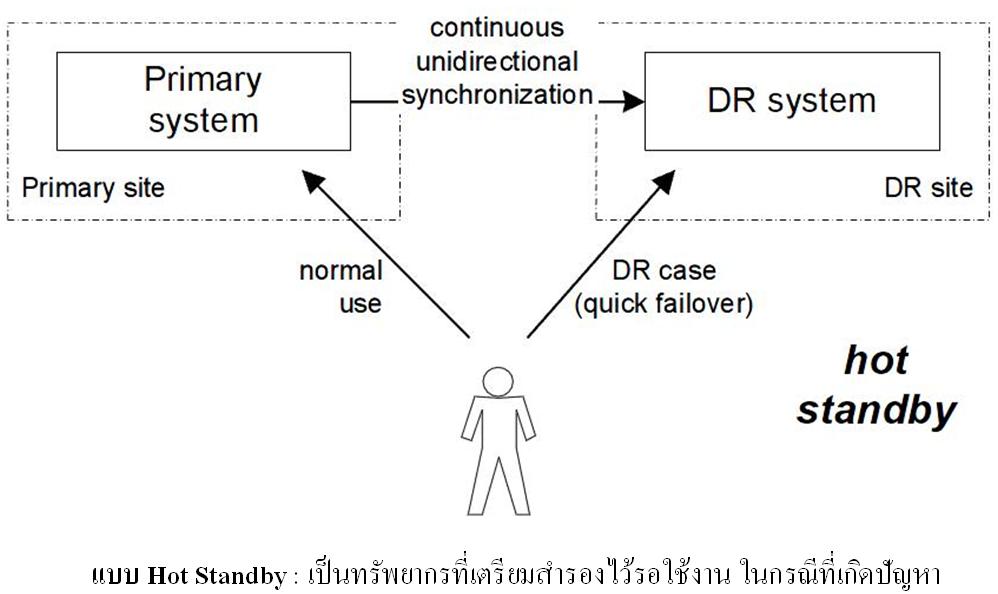
แบบที่ 3
ภาพที่ 7 แบบ Cold Standby
การวางแผนกู้คืนระบบเป็นเรื่องที่จำเป็นในวงการไอที ผู้บริหารระบบคอมพิวเตอร์และเครือข่าย ควรมีแผนงานที่ดีในการกู้คืนระบบ เพื่อลดความสูญเสียเนื่องจากปัญหาภัยพิบัติที่ทำให้การบริการไอทีเกิดหยุดชะงัก
